
Blog post
Most operations teams trust their green dashboards. If the internal monitoring says everything is healthy, the app must be fine, right? But as the Internet keeps proving, what’s green inside the firewall can look red for customers outside of it. Sometimes, a single change in how web traffic moves can suddenly slow logins, disrupt websites, or hurt business results, even if everything looks fine inside.
This happened recently to a global SaaS platform specializing in IT service management and workflow automation. When they changed their IP routing strategy (essentially, how they send traffic to customers), nothing broke internally. SLAs looked clean. But customers suffered slowed logins, and the kind of unpredictable, frustrating performance that’s often caused by spiky SSL handshakes behind the scenes.
The cause? A quiet BGP routing decision that flipped how traffic moved across the US. This wasn’t just about performance. It was a lesson in how IT decisions shape what real people experience, every day. Let’s unpack what happened, why it matters for every business, and what teams need to learn to avoid hidden pain points.
When a network decision becomes a customer issue
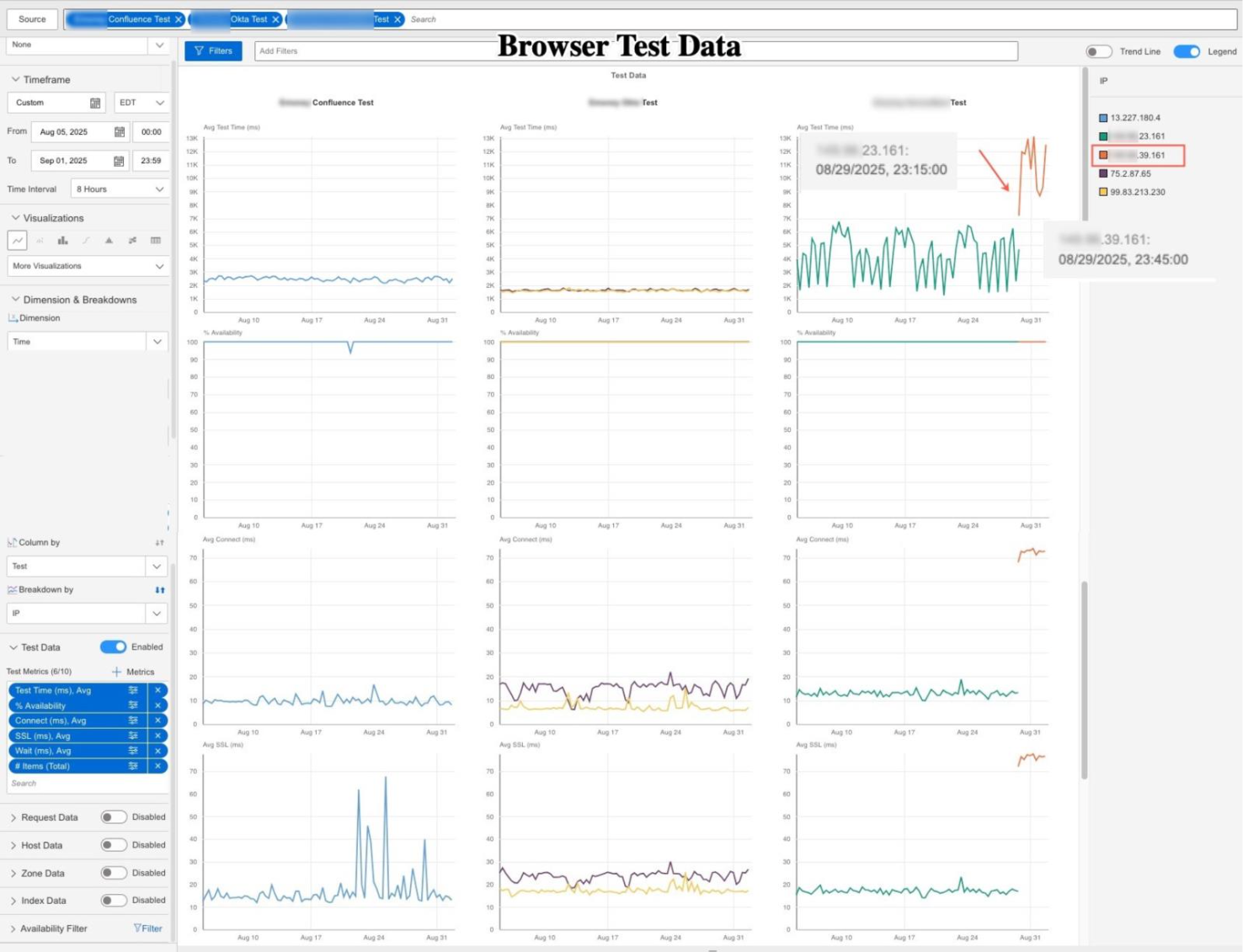
Let’s look at what actually happened to real users. Browser-based performance tests revealed just how much the routing change affected login times and security handshakes across the country, sometimes multiplying delays tenfold.
Here’s what the data showed:
What was changed: /24 vs /20
Until late August, most customers were using addresses in a specific range, the ‘/24 block’ (for the tech crowd: X.X.23.0/24) routed through a security service called Neustar. Neustar has connections across the country, which helped speed up traffic and protected users from online threats. For customers on the East Coast (like Philadelphia), this setup meant web requests reached the provider quickly, with lightning-fast response times (about 9 milliseconds) and almost no delays.
Then came the pivotal change. The SaaS provider moved customers from those addresses to a larger pool called the “/20 block.” On paper, this looked like a routine update. In practice, it was a big deal: it meant Neustar was no longer guiding the traffic. Instead, customers’ data was sent directly over the internet using providers like Lumen.
This was especially rough for East Coast users. Their requests now had to take a much longer journey, getting bounced across the country before arriving at the destination server in Phoenix. Users felt the pain immediately. Latency shot up by 10x, and basic tasks like logging in or establishing a secure connection suddenly took 5–10 times longer. For customers, everything just felt… slow.
How the changes played out in three cities
This BGP flip essentially redistributed those who suffered and who benefited. Here’s how these changes played out in three real cities, backed by the browser-based measurements you saw above:
Philadelphia (East Coast):
- Before:
Fast route (via Neustar), response time: ~9 ms
- After:
Traffic sent on a long detour through Phoenix, response time: ~61 ms
- Impact:
Local users waited over 50 ms longer for everything to load.
Denver (Midwest):
- Before:
Multiple cross-country hops, slow and shaky (~93 ms, jitter: 45 ms)
- After:
More direct path, smoother and much faster (~51 ms, jitter: 15 ms)
- Impact:
Central US users saw a big speed boost and fewer hiccups.
Phoenix (West):
- Before:
Odd detours, not local as expected (~69 ms even though they were close)
- After:
Data routed the short way, response time: ~17 ms
- Impact:
West Coast users finally got the speed they should have had all along.
But it’s not just the numbers that changed. We ran traceroute tests to map out the journey customer traffic actually took before and after the routing shift. These show each handoff along the way—from city to city and network to network—offering a clear, visual proof of what caused the delays (or improvements).

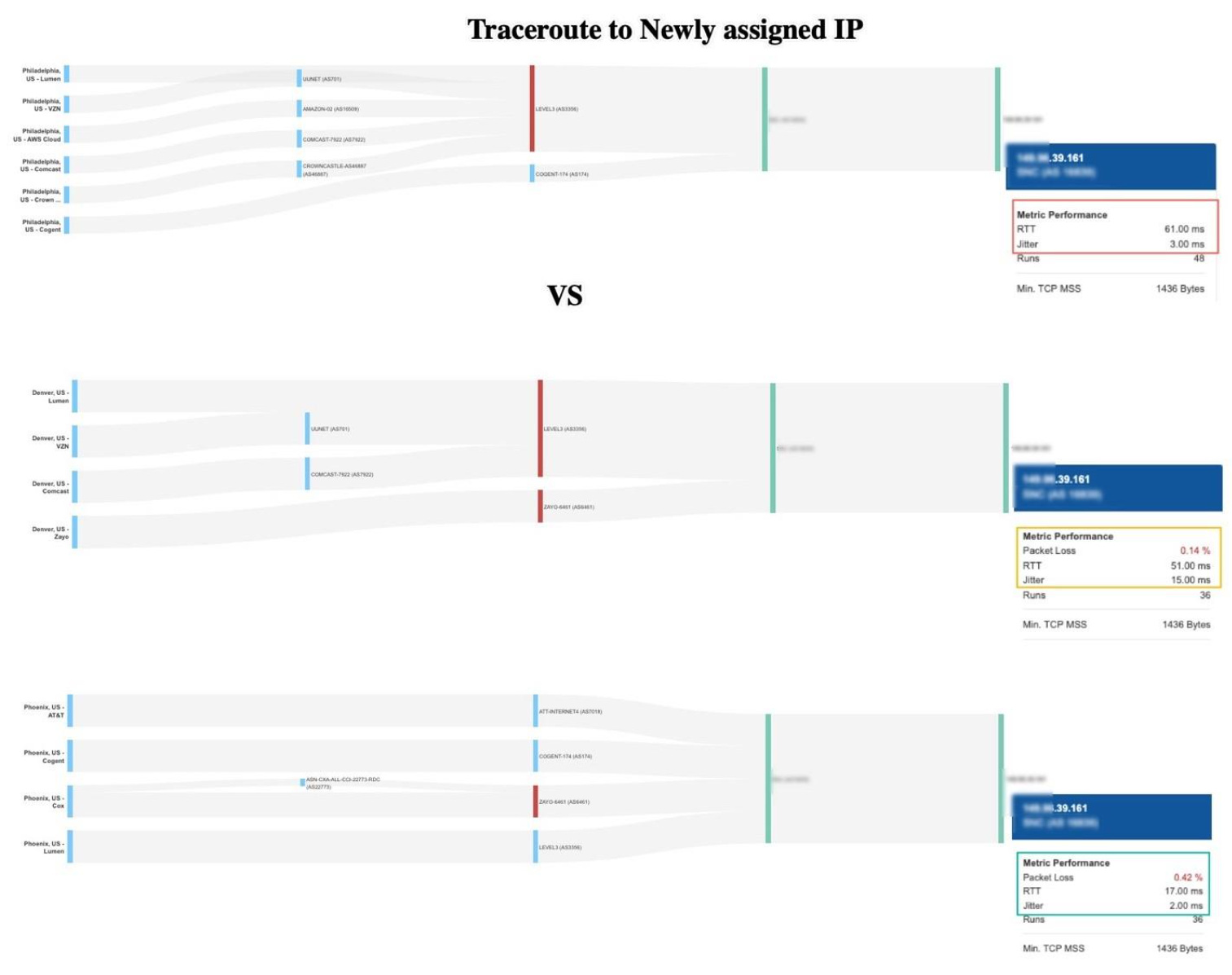
Traceroutes showing how the /24 anchored better for the East. The /20 anchored better for the West and Midwest. Neither strategy was consistent nationwide.
Why Neustar mattered, and what changed when it was removed
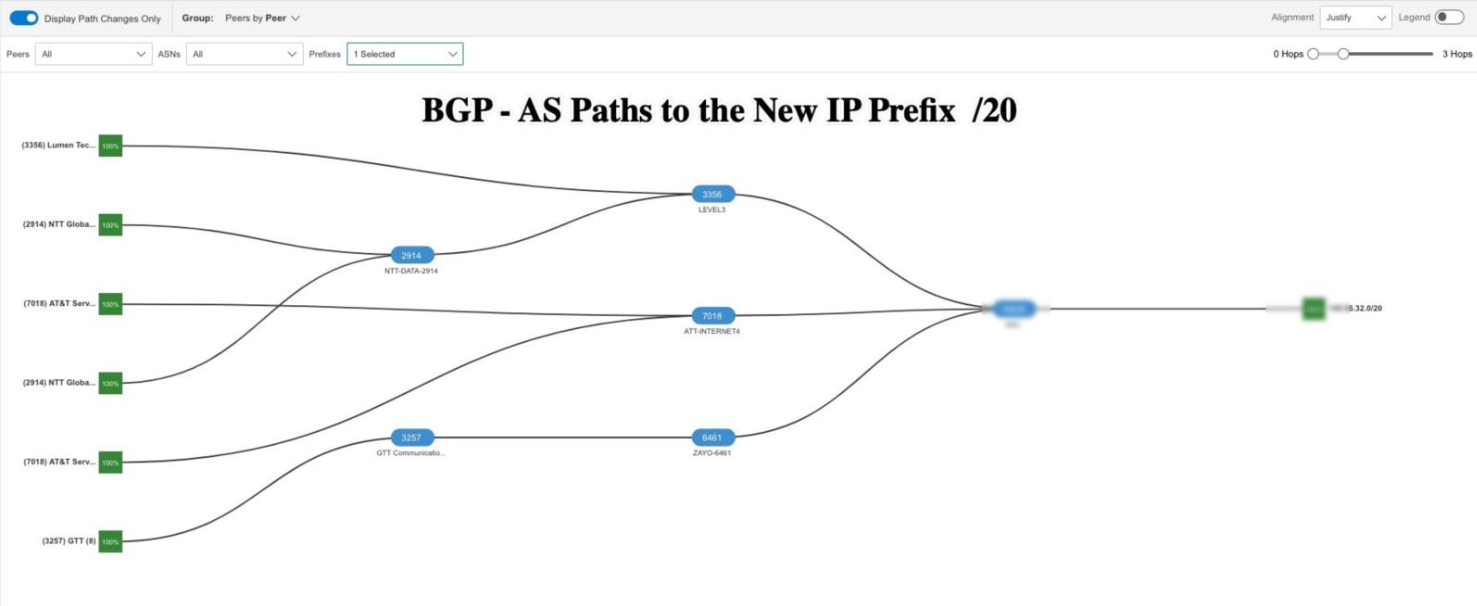
AS19905 is Vercara (formerly Neustar Security Services), widely used for DDoS mitigation and traffic scrubbing. For the SaaS platform, Neustar wasn’t just speeding up traffic, it acted as a key security and routing partner in the network. By running data through Neustar, the SaaS provider gave many customers a faster, more direct journey, with extra protections along the way. For East Coast users, this meant blazing-fast connections and a nearly flawless experience.
But this story isn’t just about latency, it’s about how the provider decided to split its network. After the routing change, some customers stayed on blocks that still pass through Neustar, getting their traffic scrubbed and distributed efficiently. Others were placed on new blocks that send data directly over major internet providers like Lumen, AT&T, NTT, GTT, or Zayo.
What’s the impact? Depending on which group you belong to, your web experience is completely different. Some users continue to benefit from both high security and fast delivery; others have a longer, less protected route, with more potential for delays.
Bottom line: Neustar’s “hidden role” meant a better, safer, and faster experience for part of the customer base. Removing it—and changing how blocks are routed—redrew the map of user pain and performance, by design.

Incident timeline
- July–August 2025: Customers primarily on X.X.23.0/24, routed via Neustar. East Coast enjoyed best performance, West Coast Users connecting to same IP were penalized.
- Late August 2025: SaaS provider moves tenants to X.X.39.0/24 within the X.X.32.0/20 block, bypassing Neustar. East Coast latency jumps, West improves overall.
- September 15–18, 2025: BGP monitoring shows X.X.23.0/24 withdrawn globally. Reachability drops to zero, confirming decommission of the old block.
- October 2025 (present): Only the /20 remains in play, with its uneven routing. This is no longer an anomaly - it is the permanent architecture.
Key takeaways for every business
Here’s what this story really shows about network changes, user experience, and why every organization should care
#1 Every BGP change can affect UX: A single prefix change can add 50+ ms to every transaction. That’s not visible on an internal dashboard but shows up immediately in user experience.
#2 Performance shifts aren’t random — they're routed: There’s rarely a universal win. Optimizing one geography often comes at another’s expense. Without broad external monitoring, you’ll never know whose experience got worse.
# 3 Security layers shape performance. The presence of Neustar as an intermediate ASN created one kind of experience; its absence created another. SaaS vendors juggle performance vs security vs cost. Sadly customers have to live with the consequences. Is there no other choice?
#4 You can’t rely on internal dashboards alone: The enterprise node in Philadelphia looked fine at layer 4. Only backbone tests and traceroutes revealed the real problem. Without external Internet visibility, ops teams would still be guessing.
How to stay ahead of BGP-driven UX surprises
From an enterprise perspective, this wasn’t about fixing an internal outage. It was about vendor accountability. With Catchpoint Internet Performance Monitoring (IPM) browser tests, traceroutes, and BGP visualizations, the ops team had undeniable evidence: the SaaS provider’s routing choice degraded East Coast performance. They could escalate with proof, not speculation.
This is why Internet-aware observability is non-negotiable:
- To catch SaaS routing shifts before customers complain.
- To understand when security layers (like DDoS scrubbing) vanish or change.
- To hold vendors accountable with hard evidence.
- To see user experience as it actually happens - outside your firewall.
The Internet is now your user experience
The Internet is now your production stack. A SaaS provider’s decision to announce a /20 instead of a /24 isn’t just a routing artifact - it’s a user experience event. East Coast logins slowed because BGP policy shifted. West Coast users cheered while Philadelphia groaned. That’s the reality of Internet-scale delivery.
Green dashboards inside the enterprise won’t tell you this. Only IPM can. Because when BGP changes, so does your customer’s experience.
Want to see how proactive BGP monitoring works in action? Request your live demo today
Summary
A global SaaS provider changed its BGP routing, which dramatically shifted user experience across the US—East Coast users suffered higher latency, while the Midwest and West saw improvements. Internal dashboards missed these regional impacts, proving only external monitoring reveals the real customer story. The lesson: Every BGP decision matters for UX, and true visibility requires looking outside the firewall.
This is some text inside of a div block.




