
Blog post
AI agents are now executing commerce transactions end to end, searching products, fetching credentials, and initiating payments without a human in the loop. With agentic systems, AI models don't just respond; they act autonomously, buying, booking, and negotiating on behalf of users.
That autonomy also introduces new monitoring blind spots that traditional observability wasn't designed to handle. This shift fundamentally changes how teams need to think about reliability.
Key takeaways:
- Agentic commerce systems like Google's AP2 let AI agents handle full transactions autonomously
- Traditional synthetic tests can't detect failures hidden inside non-deterministic AI logic
- Catchpoint IPM, part of the LogicMonitor platform, monitors both infrastructure and AI reasoning layers
- End-to-end tracing revealed Gemini rate-limit errors, merchant timeouts, and CDN origin failures that surface-level monitoring missed
The Technology: How Agentic Commerce Works
Google's Agentic Payments Protocol (AP2) is one of the first open frameworks designed to enable AI agents to handle end-to-end commerce transactions from product discovery to checkout.
Instead of a human clicking through a shopping cart, an AI agent (powered by Gemini) can:
- Interpret a natural-language intent: "Help me buy a coffee maker from Amazon"
- Search merchant catalogues through APIs
- Fetch user credentials from a secure wallet service
- Initiate and confirm payment, all through machine-to-machine communication
Behind this, a network of microservices, including merchant, payment, and credential agents, coordinates the transaction.
Each agent communicates over JSON-RPC (Remote Procedure Call), using the AP2 spec to ensure trust and interoperability between systems. All agents in AP2 communicate over JSON-RPC and follow the AP2 spec, which ensures consistent trust and interoperability even when agents are built by different teams or deployed in different environments.
This lets a shopping assistant, merchant, and payment provider coordinate securely, even if they're built by different companies or run in different environments. By enabling coordination across organizations, AP2 shows how AI can now guide and perform commercial transactions.
The Problem: Visibility Collapses When Logic Moves to AI
That new autonomy comes with a price: blind spots. Traditional synthetic tests assume deterministic logic. You click, the app calls an API, and you measure latency and response codes.
But in an agentic architecture:
- The logic is non-deterministic (driven by model reasoning)
- The execution chain spans multiple networks, LLM APIs, merchant systems, CDNs, and payment processors
- Failures are contextual, not just code-based (e.g., "Gemini throttled this request" might look like a 200 OK)
Once AI starts making the decisions, traditional visibility tools can no longer map what's happening across the full execution chain. The core challenge: how do you monitor a system that decides, learns, and acts dynamically across infrastructure you don't fully control?
Our Setup: Recreating the Agentic Stack
To answer that question, we built a functioning AP2 environment using Google's open-source agentic-commerce/AP2 repository.
The local environment included:
- Frontend: The AP2 Dev UI, hosted behind Cloudflare CDN (simulating public access)
- Origin: A tunnelled environment representing an AWS backend (FastAPI services)
- Backend Agents:
- Merchant Agent -- processes shopping queries
- Credentials Provider -- stores payment credentials
- Payment Processor -- handles mandate creation and transaction flow
- AI Brain: Gemini 2.5 Flash, invoked via Google's Generative Language API
In short, a complete AI-driven commerce stack, from intent to reasoning to payment initiation, running autonomously. We then leveraged Catchpoint Internet Performance Monitoring (IPM), part of the LogicMonitor platform, to measure performance, track latency, and identify failures across the system.

Catchpoint Internet Stack Map
Monitoring the Agentic Commerce Stack
We modelled the system using Internet Stack Map to visualize and test every layer.
Layer
What It Represents
Monitoring Method
DNS (Cloudflare)
DNS resolution and routing for the domain
DNS Monitor
CDN (Cloudflare Edge)
Edge delivery, caching, and TLS
CDN/HTTP Monitor
Origin (AWS)
FastAPI service entry point
Web Object Monitor
Backend (AP2 Agents)
Merchant, Payment, and Credentials microservices
API Monitors
AI Layer (Gemini)
Generative reasoning endpoint
API Monitor with response validation
UI (AP2 Dev Interface)
Frontend experience and intent submission
Full Browser Test & Transaction Tests with response validation
To connect these layers, we used Catchpoint IPM's global variable extraction to capture the session ID generated in the UI synthetic test and reuse it across multiple backend API tests. Tests ran every 5 minutes from global agents.
The UI synthetic flow traces a user journey from the browser prompt ("Help me buy a coffee maker") through the multi-agent orchestration, cart creation, payment mandate signing, and final payment receipt. Using Catchpoint synthetic E2E flow testing and Internet Stack Map, we get the following:
Transaction correctness: verifies that intent → cart → payment_mandate → signed_mandate → payment_result flows and that the transaction state is persisted across agents.
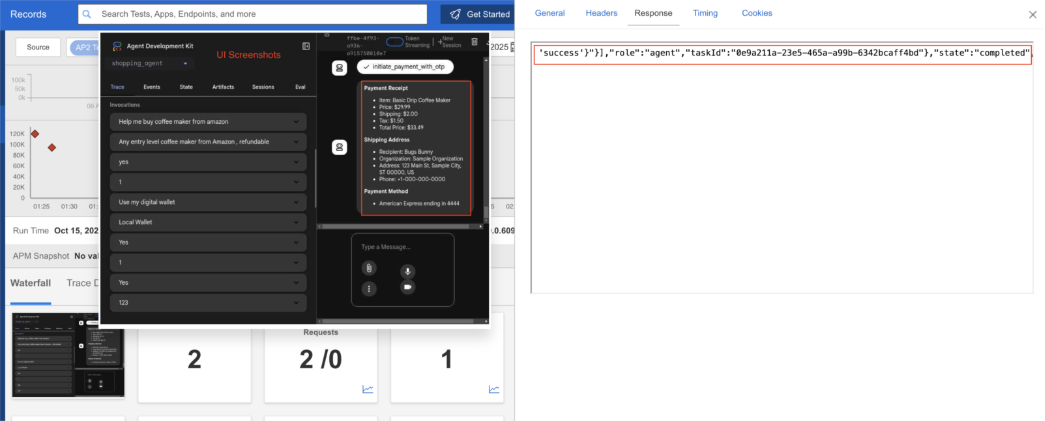
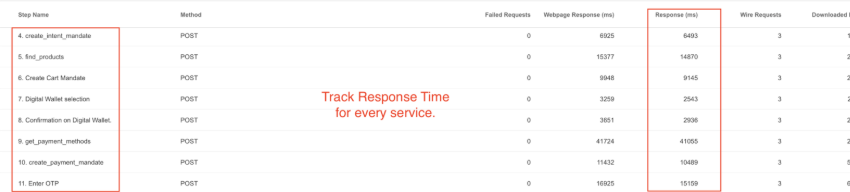
Per-service performance: measures response time for each service/agent (create_intent_mandate, find_products, create_cart_mandate, get_payment_methods, create_payment_mandate, sign_mandates_on_user_device, initiate_payment). This converts "who's slowing down the transaction" from guesswork to data.
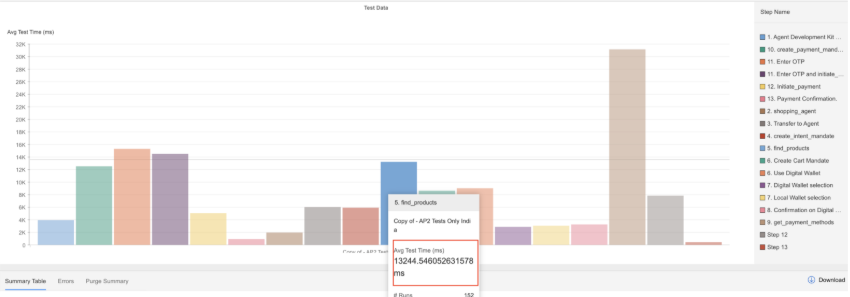
In the example below, we see find_products alone took 13 seconds to fetch all product SKUs.
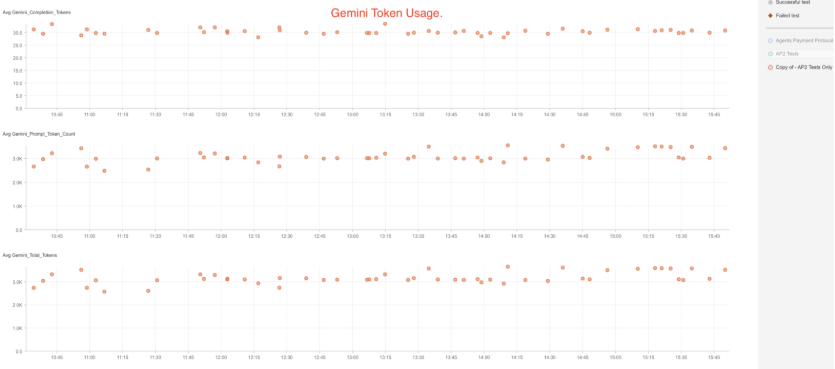
Token consumption visibility: tracks model token usage (prompt, completion, total) per run so you can spot cost anomalies or prompt drift.

Waterfall & Explorer insights: waterfall traces and explorer request/response bodies surface the exact failing/requesting call and payload, enabling fast root cause analysis.
Stack map correlation: connects failing runs to observed infrastructure components (CDN, edge, middleware, origin) to locate the root cause quickly.
Key Blind Spots We Found
End-to-end AI commerce monitoring with Catchpoint IPM surfaced a few real-world failures that would otherwise appear as generic "assistant unresponsive" events.
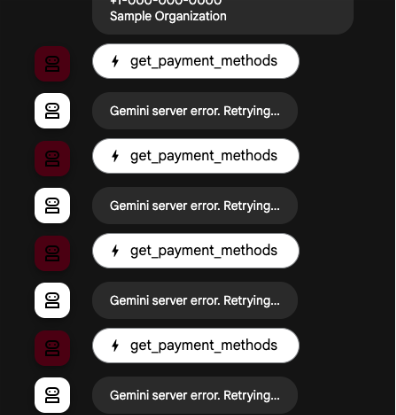
1. Gemini Errors
When we began testing, the system looked healthy and all endpoints returned 200 OK. But deeper inspection revealed Gemini 429 errors hidden within successful responses.

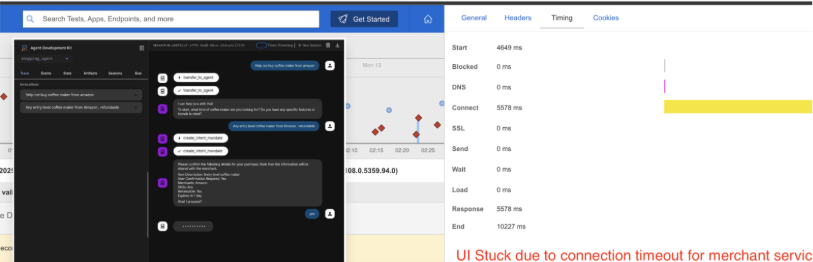
2. UI Stuck Due to Merchant Service Timeout
- The front-end chat interface froze after create_intent_mandate
- Catchpoint Explorer and Timing breakdown revealed a connection timeout (~10s) while waiting on the merchant agent service
- The delay was isolated at the connect phase, confirming that the issue occurred before payload transfer, likely a temporary connectivity or backend overload condition
- Stack Map correlation showed this hop passing through Cloudflare → Apigee → Merchant microservice, pinpointing the bottleneck to the merchant layer
3. UI Down: 530 Error From Cloudflare
- Synthetic UI tests later reported complete inaccessibility with an HTTP 530 (Origin Error) response
- The error originated at the CDN edge (Cloudflare), meaning requests never reached the origin host
- Catchpoint's full waterfall and DNS tracing confirmed normal DNS resolution and SSL handshake, isolating the fault to Cloudflare's route-to-origin link
- Because the 530 surfaced at the UI layer, RUM or browser logs alone would have masked it as "page load failed"


AI assistants are multi-layered systems where a "slow model" isn't the only possible culprit. By combining synthetic testing, end-to-end performance tracing, and cross-layer correlation, teams can pinpoint exactly which agent or network segment caused a stall, whether it's a Gemini model delay, a merchant service timeout, or a CDN origin error.
Evolving Observability for AI-Driven Systems
As AI systems begin to transact independently, observability must extend beyond servers and APIs into the logic that drives decisions. With Catchpoint IPM, organizations can monitor AI commerce environments across both the infrastructure and reasoning layers, gaining visibility into the AI's decision logic, execution path, and failure points.
Agentic systems like AP2 are early prototypes of a broader shift, where applications become autonomous agents orchestrating workflows in real time. When that happens, performance data will no longer be about page loads or API speeds alone. It will be about intent execution: the AI's ability to fulfil a task successfully across systems.
By unifying LM Envision, Catchpoint IPM, and Edwin AI into one Autonomous IT platform, LogicMonitor extends observability from systems to intelligent decision flows, giving teams the visibility they need to keep AI-driven operations reliable.
Learn More About AI Monitoring
Summary
When AI agents buy, book, and negotiate autonomously, observability must evolve. Using Google’s AP2 framework and Gemini model, we built a full agentic commerce stack and instrumented it end to end. The findings reveal where visibility breaks across LLM reasoning, microservices, and networks, and how synthetic testing and Stack Map restore traceability and root-cause insight.
This is some text inside of a div block.




