
Blog post
One Large Language Model (LLM) nails your brand’s tone but drifts after a model update. Another is lightning fast until it spikes in latency during peak hours. A third delivers brilliant answers except in specific regions where it falters.
Why Choosing (and keeping) the right LLM is so hard
Across all types, from open-source to proprietary, LLMs are dynamic, not fixed. They update silently. They hallucinate unexpectedly. They cost more (or less) depending on use. And they perform differently based on geography, task, or input.
That makes it hard to trust that the model you chose yesterday is still the best option today.
What teams need is a way to continuously evaluate the LLMs they rely on - to compare, validate, monitor drift, and surface anomalies before users do. Not just once during procurement-but every day in production.
TL;DR: LLMs are powerful, but unpredictable. Their performance, accuracy, cost, and safety can change without notice. That’s why continuous monitoring and real-world testing are essential. Instead of treating LLMs as static tools, teams now test and compare them regularly to ensure they keep delivering reliable, relevant, and cost-effective results.
Types of LLMs and what they mean for monitoring
LLMs come in various forms-fully open-source, closed-source APIs, and hybrid models.
Open-source LLMs allow you to access, modify, and self-host the model weights and sometimes training data/code.
Closed-source models (e.g., GPT-4, Claude) are proprietary and accessed via API.
Hybrid models may be hosted by providers but expose some architecture or tuning capabilities.
Open-source advantages:
- No licensing costs
- Greater flexibility (especially on-premise use)
- More transparency (to varying degrees)
Open-source LLMs offer flexibility and transparency, but the real challenge, open or closed, is monitoring and maintaining model trust over time.
How do AI agents choose the right LLM?
Modern AI agents often route tasks to different models depending on the need. Their choice depends on:
- Task type - reasoning, creativity, retrieval, real-time queries
- Performance goals - speed, cost, consistency
- Security needs - private infrastructure vs. cloud
Before routing, an AI agent typically receives user input, anything from a question to a task request, via a front-end interface like a chatbot or form.
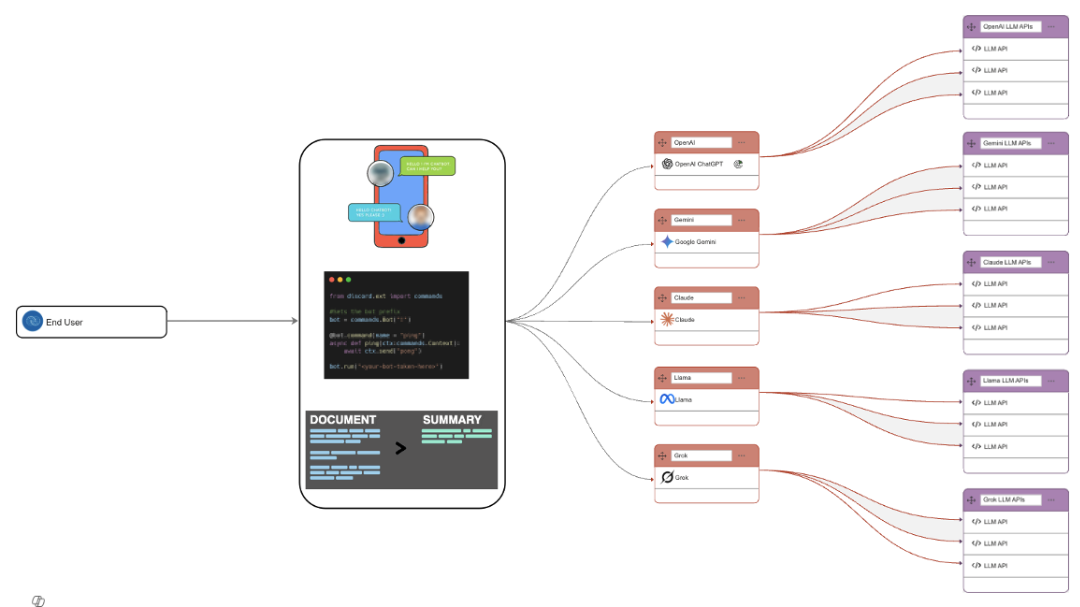
AI agents act like routers, matching each prompt to the best-fit model using business logic.
Common LLM routing scenarios:
- GPT (OpenAI): Ideal for research-heavy, general-purpose text generation.
- LLaMA: Lightweight, open-source alternative for on-premise or private setups.
- Gemini: Good for reasoning and integrating with Google ecosystem.
- Grok: Chosen for video generation or multimedia-related queries.
- Claude (Anthropic): Safer alignment in regulated domains
A condition-based logic is used: e.g., “If input involves video processing → use Grok”.
Once an LLM is chosen, the real challenge is ensuring it continues to perform. This is where Catchpoint’s monitoring comes in.
Catchpoint’s approach to testing and monitoring LLMs
Catchpoint's LLM monitoring framework evaluates how models perform across a wide range of tasks, from summarization to code generation, and measures how reliably they respond to real-world use cases. With over 3000 Intelligent Agents, it’s possible to rigorously monitor the health, quality, and latency of LLM responses, whether from GPT, Claude, Gemini, or another platform.
In practical terms, that means:
- Sending live prompts to multiple LLMs across geographies
- Capturing how each responds (tone, coherence, freshness)
- Identifying issues like drift, hallucination, or performance degradation
This is a repeatable testing framework for users evaluating generative AI use in their workflows. It helps de-risk LLM adoption by offering visibility, choice, and control.
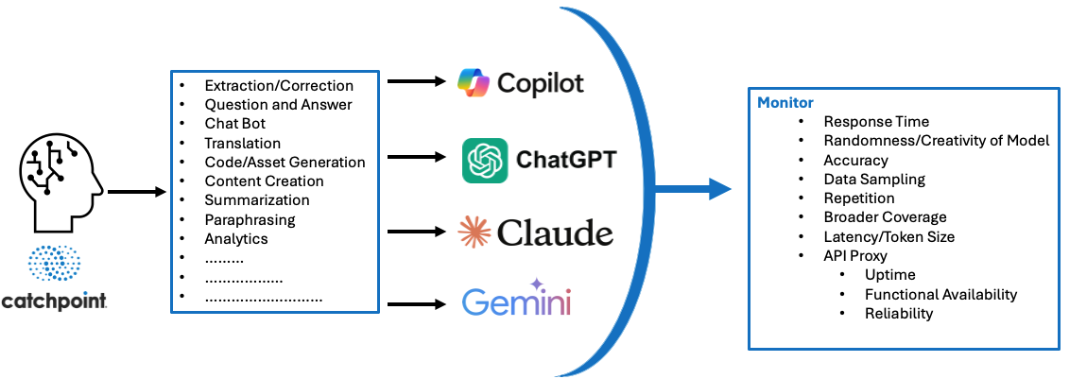
Some core capabilities tested include:
- Interpret prompts and generate natural language responses.
- Provide multiple perspectives on the same input.
- Demonstrate behavior under various hyperparameters.
Key API parameters that shape LLM behaviour
A model’s response style depends not just on its architecture, but on how it’s configured via prompt parameters. These control randomness, verbosity, and tone-and small tweaks can produce drastically different results.
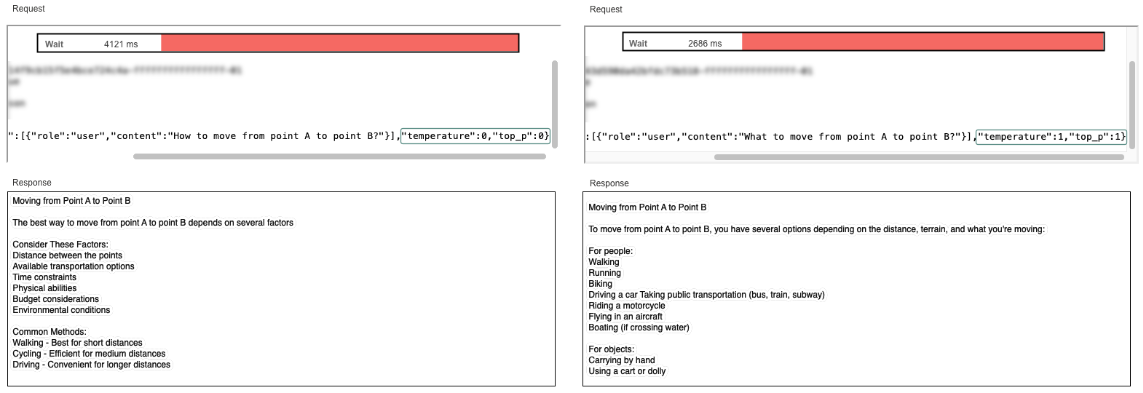
Below: A sample request sent to an LLM API, showing how:
- Key parameters help structure the response
- Key metrics should be tracked to make sure quality of response and performance is metered equally
Catchpoint also uses scripts like the one below to send prompts to multiple models and compare outcomes.
Catchpoint Script Sample
var apiURL = "https://abc.com/models/openai | anthropic | google";
var apiData = {
"messages": [
{ "role": "user", "content": "What does Catchpoint do?" }
],
"temperature": 0.7,
"top_p": 0.9,
"frequency_penalty": 0.3,
"presence_penalty": 0.1,
"max_tokens": 500
};
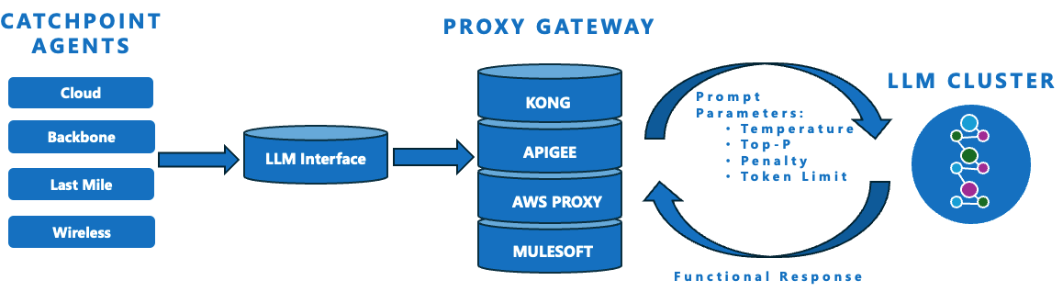
API Parameters and their Use Cases
These tuning parameters control how an LLM responds-from the length and style of the output to how creative or focused it should be. Small changes here can dramatically affect tone, accuracy, and cost.
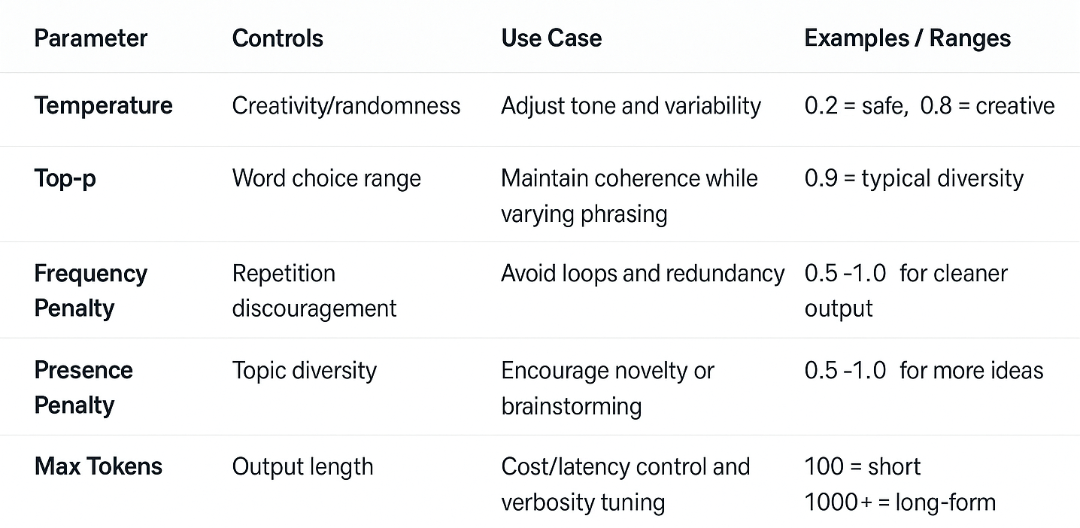
Pro Tip: Use either Temperature or Top-p for tuning style-not both. Fine-tuning these variables is essential for aligning model behavior to business goals.
Why benchmark and compare LLM performance with Catchpoint
To understand how LLMs behave across tasks, Catchpoint tests multiple models using a consistent framework. This helps compare tone, latency, cost, and more.
Teams can:
- Send the same prompt to multiple models (e.g., GPT, Claude, Gemini)
- Measure latency, style, accuracy, and cost side-by-side
- Detect model drift-when output changes unexpectedly
- Test fallback routing logic when a model degrades or fails
- Simulate regional prompts for localization or compliance
In one recent multi-model test, Catchpoint recorded latency spikes exceeding 27 seconds for a local deployment, while OpenAI maintained higher but more stable response times than Claude or Gemini.
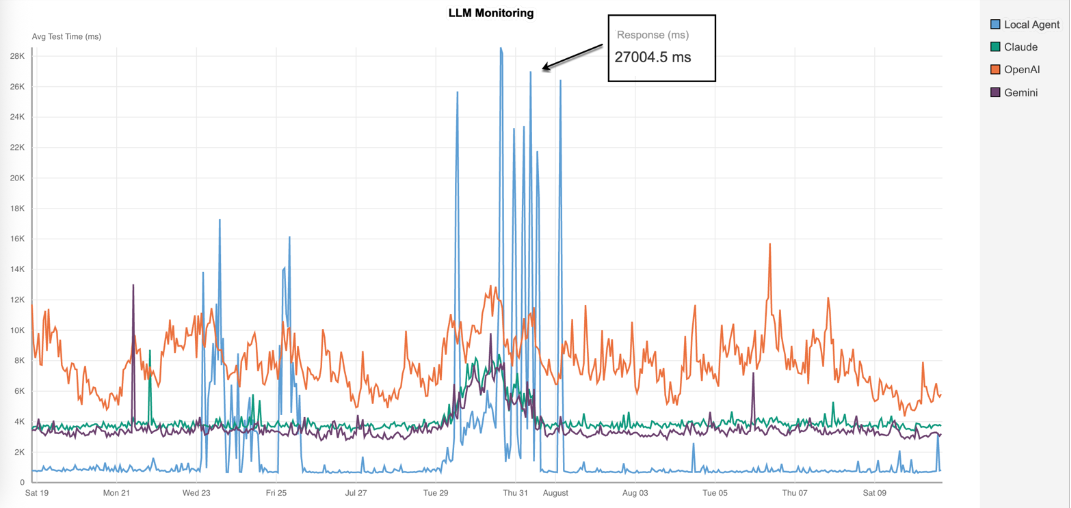
The graph above shows results from the same customer test, with each line representing a different LLM responding to the same prompt under controlled conditions. The variations highlight both transient spikes and sustained latency patterns, giving teams the evidence they need to assess performance and reliability. Detecting these anomalies early allows Catchpoint customers to trigger fallback routing automatically, switching to a backup model before users are impacted.
From benchmarking to continuous monitoring
Catchpoint’s vendor-neutral platform enables customers to evaluate, compare, and orchestrate multiple LLMs from a single interface. In the example below, that approach revealed 100% availability for Claude, OpenAI, and Gemini during the test period - but also clear differences in average response time, from 3.3 seconds for Gemini to 6.8 seconds for OpenAI.
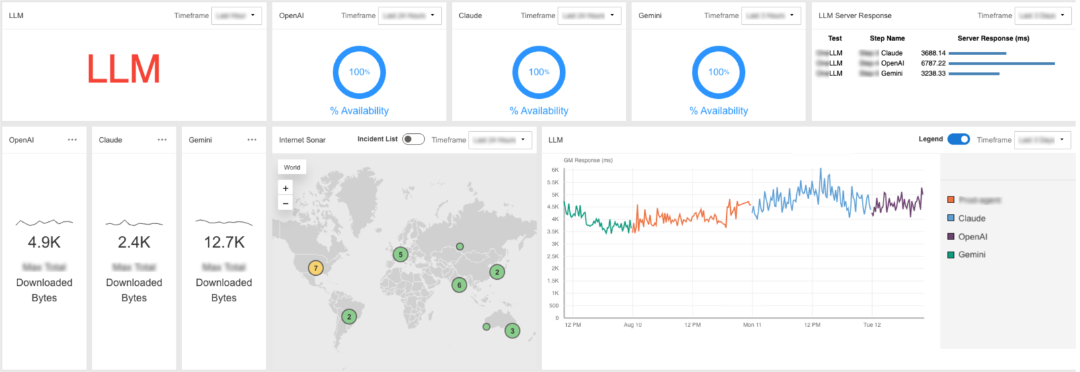
The dashboard also tracks downloaded byte volumes, which can highlight efficiency differences between providers, and maps incidents geographically so teams can pinpoint where performance issues occur.
By combining these metrics with prompt-level scoring, Catchpoint gives teams an end-to-end view of LLM performance. That includes not only the quality of model responses, but also the reliability of API gateways, proxies, and network paths that can affect delivery.
Here’s what that looks like in practice:
- Evaluate model tone, cost, and performance before integration - Test accuracy, tone, style, and brand voice alignment against your own data before committing to a model.
- Continuously monitor LLM drift, hallucination risk, and latency across APIs - Detect subtle output changes, tone/style mismatches, or quality regressions before they reach end-users.
- Run side-by-side tests with prompt scoring and fallback logic - Measure output quality and validate automated failover strategies.
- Track gateway and proxy reliability to ensure end-to-end LLM delivery - Confirm the entire request path is healthy, not just the model itself.
- Adapt tests to any model, deployment style, or geography - Apply the same monitoring approach to cloud-hosted, on-premises, or hybrid LLMs worldwide.
- Test for security and safety compliance - Use synthetic prompts to trigger edge cases and validate that models meet responsible AI guidelines.
FAQ
Q: Can I monitor LLMs running on my local infrastructure as well as globally?
A: Yes. Catchpoint synthetic agents and local test runners can validate self-hosted LLMs for accuracy, latency, drift, and availability - just like cloud-hosted models. This lets you measure performance both inside your network and from global vantage points.
Q: Does Catchpoint support both open-source and closed-source LLMs?
A: Absolutely. Whether your model is fully open-source, API-only, or hybrid, Catchpoint’s vendor-neutral framework can run side-by-side comparisons, measure performance, and track quality changes over time.
Q: How often should I schedule drift and degradation tests with Catchpoint?
A: We recommend testing aggressively; high-risk or regulated environments may benefit from checks every millisecond. Catchpoint can automate these tests and trigger alerts as soon as drift, latency spikes, or quality regressions are detected.
Q: Can Catchpoint test multiple LLMs at the same time?
A: Yes. You can send the same prompts to multiple providers - such as GPT, Claude, and Gemini - and compare their responses for tone, accuracy, latency, and cost. This side-by-side testing makes it easy to identify the best model for each use case and switch if performance changes.
Final takeaway
LLMs aren’t static assets - they’re constantly evolving, often in ways that affect accuracy, cost, and reliability without notice. In production environments, this means “set it and forget it” is not an option. With Catchpoint, teams can continuously verify performance across providers, regions, and deployment models, detect drift or regressions before they impact users, and validate failover strategies under real-world conditions.
By operationalizing trust with measurable metrics - from latency and availability to tone and brand alignment - you turn LLM monitoring from a reactive chore into a proactive advantage. The result is faster issue resolution, higher model reliability, and a clear understanding of which LLM is the right fit at any given moment.
Learn more about Catchpoint’s AI monitoring solutions
- Agentic AI Resilience - Monitoring AI agents, orchestration logic, and toolchains that rely on LLMs to ensure end-to-end resilience.
- Monitor AI Assistants - Track the performance and reliability of AI-powered assistants like chatbots, copilots, and digital agents across regions and providers.
Summary
This is some text inside of a div block.




