API (Application Programming Interface) is the most common method for connecting clients to various services in modern web applications and microservices. An API gateway is a crucial bridge that manages, secures, and optimizes the data flow. However, one of the key challenges in pursuing optimal API performance is API gateway timeout errors.
This article explores API gateway timeout, why it happens, and how to avoid it with examples and implementations.
What is an API gateway?
An API gateway is a server or managed service that processes API requests from clients seeking resources from backend services. It uses predefined policies to provide key functions, simplifying and managing the interactions between client applications and backend services. In most cases, an API gateway passes requests through multiple microservices and aggregates the results to the end user for a simplified user experience
How API gateway works
An API gateway works by sitting in between clients and services. Once it accepts any client requests, it channels them to the relevant backend services and gathers all the responses together. It routes client requests to various services by acting as a reverse proxy.
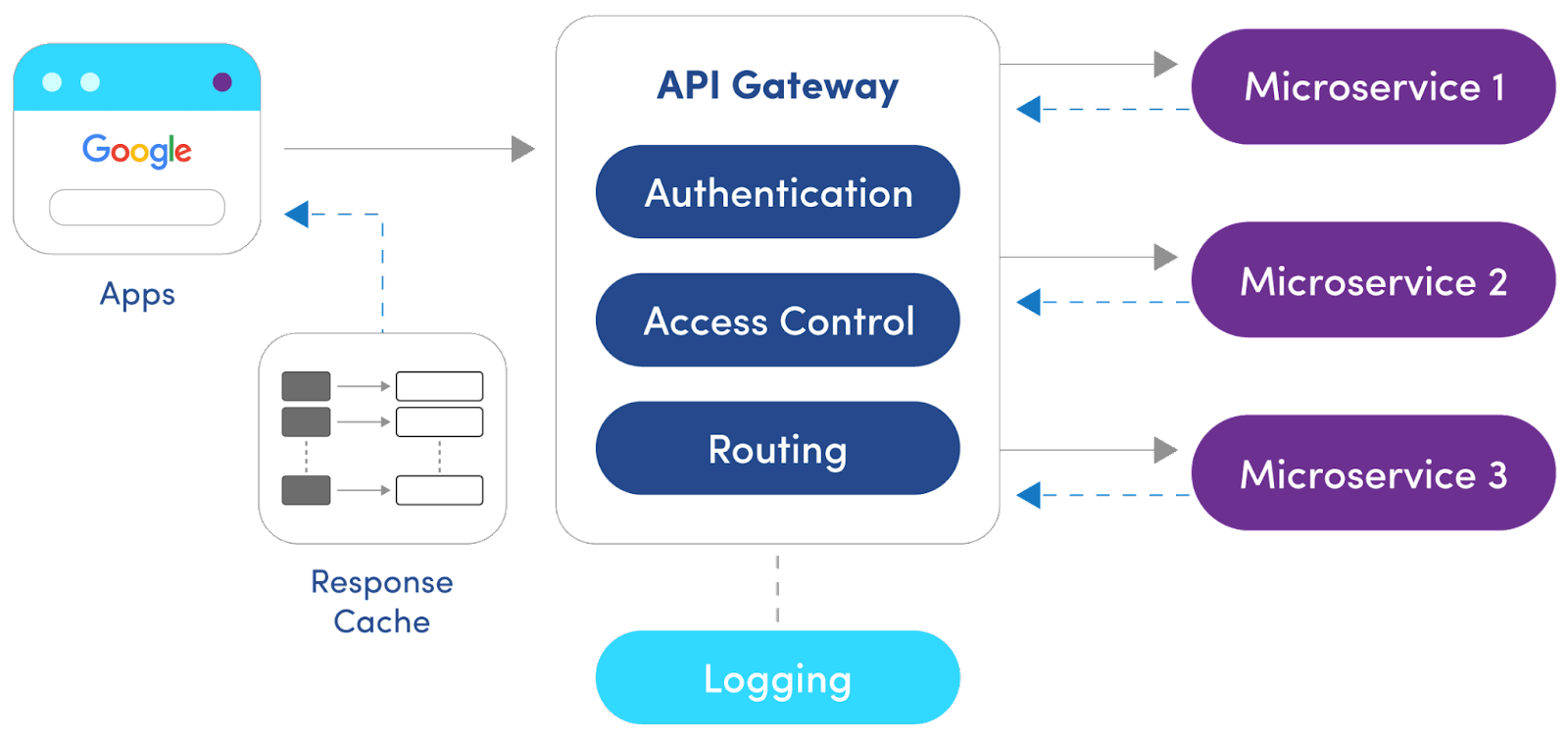
API gateway primarily implements routing policies with access control. It is also common to implement authentication, security, logging, and monitoring policies in an API gateway. It can be extended for additional security with security measures such as SSL, DDoS protection, WAF, etc.
What is API gateway timeout?
In a microservice environment, API gateway timeout is the total time available for an API gateway to process a request from a client by routing it to relevant services and returning the response to the client. The API gateway throws an error (usually with the status code 504) when it does not receive a timely response from the upstream services it needs to complete the requests. An API gateway timeout is the maximum time the gateway waits for a request-response cycle from a client to the backend services.
Types of API gateway timeout
Some of the common types of API gateway timeouts that might occur on specific phases or components are given below.
Common causes of API gateway timeout
API gateway timeout occurs for various reasons. Some of the common causes are given below.
Server overloads
When the backend services of an API gateway get overwhelmed with many requests, they become slow and unresponsive, leading to API gateway timeouts. Sometimes inadequate server resources or inefficient codes can also cause server overloads. A huge surge of traffic above the capacity of the backend services can also overload a backend service.
A tool like LogicMonitor Tracing can report on server request and response metrics so you can quickly identify and fix issues. Teams can include critical business KPIs and digital experience-based signals into their observability frameworks for consistent user performance.
Network issues
If the connections between the API gateway and the backend services become unreliable due to high latency, packet loss, DNS/BGP issues, or congested network links, the requests-response cycle becomes slow. This delay propagates and causes API gateway timeout.
Active monitoring and real-time alerts are required to detect and mitigate network issues. For example, LogicMonitor's tracing and BGP monitoring tools have the ability to cycle through different testing locations, which is very rare yet extremely effective in finding regional network issues and bottlenecks.
Unoptimized DB queries
Inefficient and poorly optimized database queries can cause API gateway timeout. As the data grows, backend services with slow database queries become slower and slower. Eventually, if these services remain unoptimized, they become unusable. Besides, N + 1 queries are also common causes of API gateway timeout, which can easily be mitigated by removing the loops.
LogicMonitor Tracing has built-in capabilities to detect unoptimized database queries for enhanced application performance.
Long-running tasks
Backend services that perform time-consuming computations, such as complex algorithmic calculations or data processing, are prone to API gateway timeout issues. If the task takes too much time, the API gateway throws a timeout error after waiting for a certain period of time.
Resource exhaustion
When a backend service exhausts its resources, such as CPU or storage, it may become unresponsive, leading to API gateway timeout. Sufficient resources should be allocated to avoid resource exhaustion.
Best practices to avoid API gateway timeout
To avoid API gateway timeouts and ensure your API remains reliable, it’s crucial to implement a set of best practices. These best practices can be categorized into two subcategories—serverside and clientside.
Serverside practices
If the backend services aren’t optimized well, then the API gateway performance suffers. So, backend code and DB queries should be well optimized in order to avoid API gateway timeout. You can implement the following changes in your backside services to reduce API gateway timeout errors.
Proper caching strategy
Caching frequently requested data reduces loads on the API gateway. Implementing a caching mechanism to store data and quickly serve them greatly reduces API gateway timeout issues. However, extra care should be taken to ensure no stale data issues. Static assets can be served using a content delivery network(CDN) and cache headers can prevent the stale data issue while implementing a caching strategy.
Set requests throttle and rate limit
One of the key reasons for API gateway timeout is server overload. To prevent server overload, set request throttling and rate limiting. You can control incoming requests and prevent overloading of the backend services. The limits should be set based on the server capacity and usage.
Use asynchronous processing
Instead of long-running tasks, use asynchronous processing. Splitting the long-running tasks into chunks of sub-tasks that can be run in parallel to each other saves resources and execution time, which yields better API gateway performance. In some cases, if splitting isn’t possible, consider offloading resource-intensive operations to queues and background workers.
Error handling and retry management
Implement robust error handling that smoothly handles errors and exceptions. Setting up automatic retries for failed requests can improve the client experience and give the backend services chances to recover from the failure.
Implement circuit breaker pattern
Failing or slow backend service hampers the performance of other services. Especially if the API gateway is designed to retry failing requests multiple times, the issue can escalate really quickly. To prevent this escalation, implement a circuit breaker pattern so that the circuit breakers can temporarily block the failing requests. This prevents the further degradation of the services.
Synthetic monitoring and alerting
Implementation of synthetic monitoring coupled with alerting mechanisms, serves as a proactive strategy to avoid API gateway timeouts. Simulating user interactions and conducting scheduled tests establishes performance baselines, enabling early detection of issues and deviations. Using LogicMonitor's synthetic monitoring tool, it’s possible to perform continuous analysis of test results, provide valuable insights for iterative optimizations of API gateway configurations, and plan capacity while ensuring the potential problems are identified before impact.
Clientside practices
Client-side practices refer to API gateway configurations that optimize client request handling
Concurrent requests management
Managing concurrent requests ensures a smooth user experience. You can optimize client-side code, distribute tasks efficiently through concurrent requests, and scale horizontally to prevent overloading and timeouts while keeping the user interface responsive. In some cases, you need to pay extra attention to the number of concurrent requests, as modern browsers have a maximum limit for connections per domain. For example, Google Chrome allows six connections per domain, other browsers have a similar default value.
Cache responses
Caching on the client side is equally important as serverside cache. Caching frequent requests on the client side can reduce the number of requests and API calls significantly. It also optimizes the response times.
API usage optimization
You can minimize the data transfer to the bare minimum in response, avoid unnecessary calls, and utilize batch processing to enhance API performance. By streamlining the interaction between clients and APIs, you can reduce the risk of timeouts to a greater extent and conserve resources.
Exponential back-off
The exponential back-off approach gradually increases the time between successive API retries when facing temporary service disruption. By dynamically adjusting the retry intervals, you increase the chance of success. It’s a proactive measure to gracefully handle potential API gateway timeouts and maintain reliability.
Active monitoring
Active monitoring continuously observes and analyzes real-time data. It can help you actively detect performance irregularities, and allow swift responses whenever an issue arises. By correlating active monitoring data with synthetic monitoring, you can also understand system behavior more comprehensively. Active monitoring adds real-world dynamics on top of the predefined baseline set by synthetic monitoring, further reducing the risk of API gateway timeouts in dynamic environments.
API gateway timeout implementation in AWS
Let’s consider the following serverless project—the below diagram is a simplified version of the original project, that only highlights a few of the microservices under the AWS API Gateway. All the clients from web applications or mobile apps connect through the gateway. The AWS API Gateway handles authentication, logging, and WAF along with the logging.
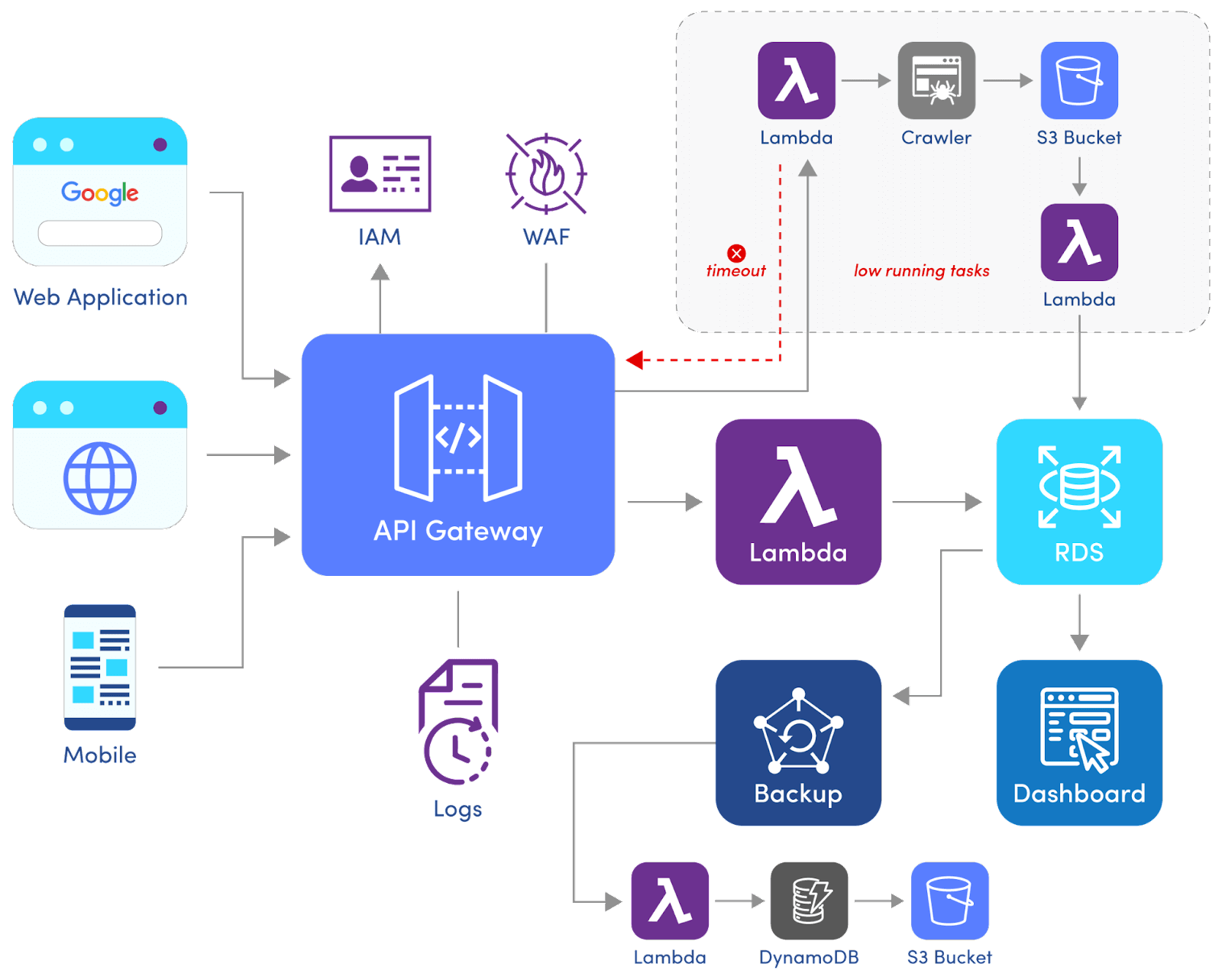
Notice the highlighted long-running tasks that are currently throwing an API Gateway timeout when the traffic is high. The problem with this implementation is that the Lambda function is used for triggering the Crawler service on demand, which performs extractions of data from the target websites in real-time, returning the result to another Lambda function and storing the results and assets to the storage. This works on a small scale when traffic is low. However, as the traffic grows, this particular endpoint becomes slower and starts to throw timeout errors since the backend service takes way longer to process the incoming requests.
A possible solution is to move the Crawler service to a background task queue and periodically crawl the data and store them in the storage. This offloads the affected endpoint and makes it faster. The implementation looks similar to below:
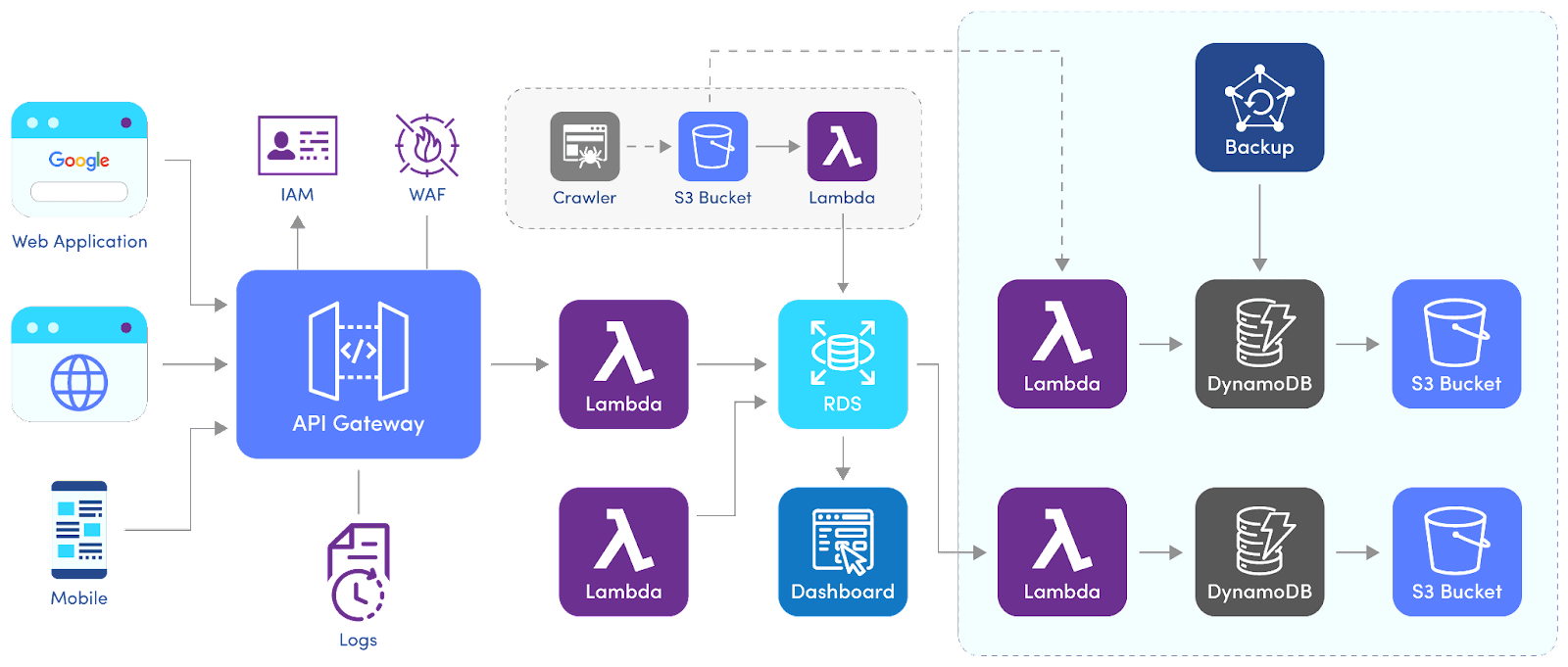
As you can see, the endpoint’s Lambda function computes the data from the RDS almost instantaneously and doesn’t directly rely on the Crawlers for processing the requests. The backup of the crawled assets from the S3 bucket is also moved from RDS to a separate process, further improving the database's performance.
One thing to keep in mind is the AWS API Gateway timeout’s default timeout setting is 29s, however, it is possible to set it lower by configuring the resources of the API.
AWS API Gateway timeout configuration
The API Gateway timeout configuration is fairly straightforward. You can set the timeout when creating endpoints for the REST API resources in the Amazon API Gateway. From `API Gateway > APIs` navigate to your desired `API` and define the method as below:
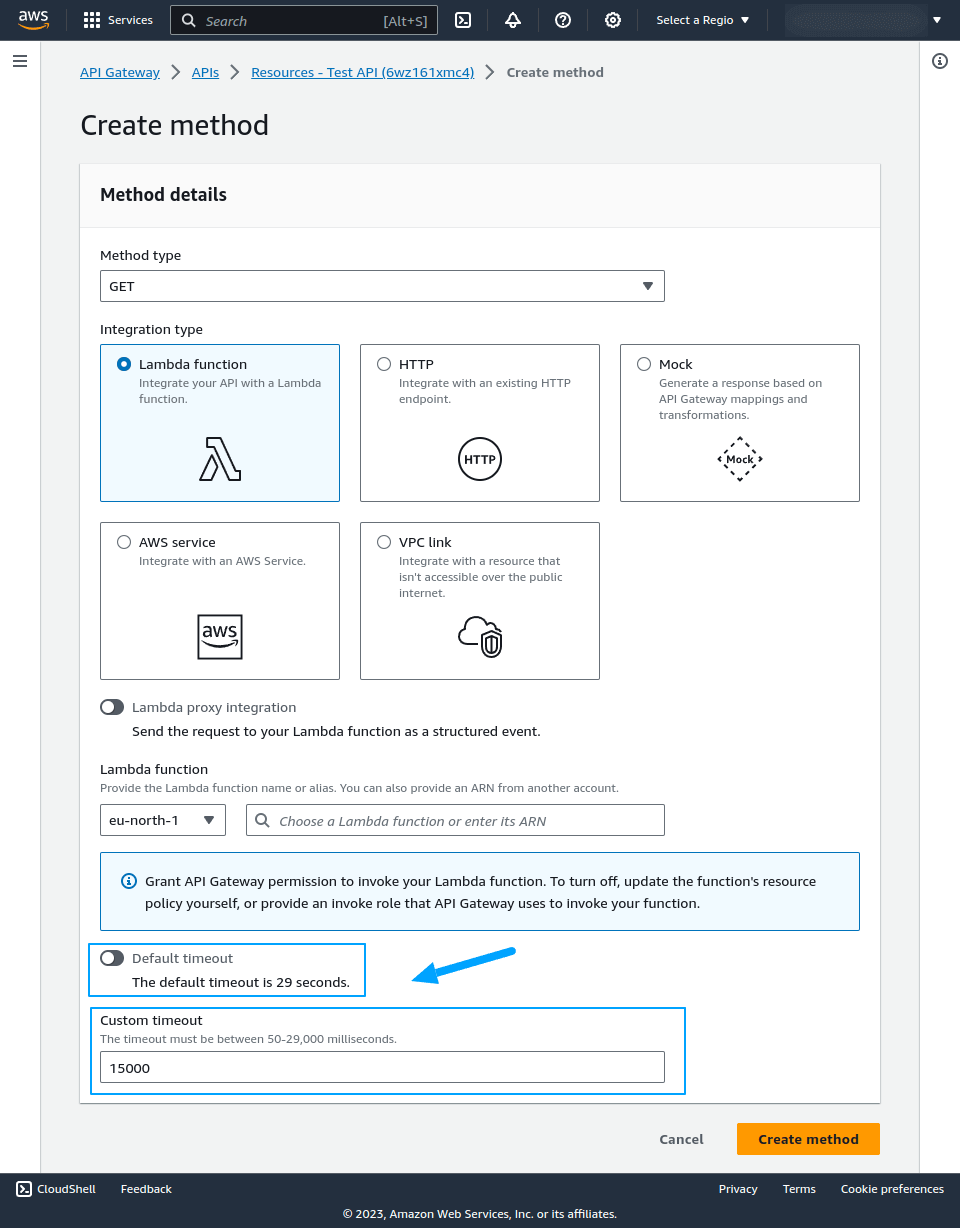
By default, Amazon API Gateway sets a timeout of `29s` You will have to toggle the `Default timeout` settings shown above to view the `Custom timeout` settings. We’ve set the timeout to `15s` in the above example. The maximum limit for the AWS API Gateway default timeout is 29 seconds. If your Lambda function requires a longer execution time, it will result in a timeout error.
Common ways of dealing with API gateway timeout in AWS Lambda
Dealing with API gateway timeout in AWS Lambda requires a strategic approach. The main goal is to reduce Lambda function execution time so that it is under the timeout settings value. If Lambda performs multiple tasks, it is better to split them into smaller functions and distribute them to multiple Lambda to run them parallelly and reduce the overall compute time. If parallel computation is impossible, offload the computation and processing using Asynchronous services such as SQS, SNS, etc. Also, ensure exponential back-off strategies are properly implemented with cache integration to reduce the load on Lambda by caching results of the frequent compute requests.
API gateway timeout in other public cloud providers
Both Google Cloud Platform and Microsoft Azure provide convenient ways to customize API gateway timeout settings. We’ll learn how to configure the API gateway timeout in GCP and Azure in the below sections. Other cloud providers also have a similar way of configuring the timeout, just check the appropriate documentation sections.
GCP
To configure the API gateway timeout for the backend services, use the deadline parameter of the `x-google-backend` OpenAPI extension. It’s possible to customize the timeout settings for each endpoint. For example, take a look at the below sample `openapi2-functions.yaml` file:
swagger: '2.0'
info:
title: sample-api
description: Sample API on API Gateway
version: 1.0.0
schemes:
- https
produces:
- application/json
paths:
/microservice_1:
get:
summary: Microservice 1 endpoint
operationId: microservice_1
x-google-backend:
address: https://microservice_1
deadline: 75
responses:
'200':
description: Success
schema:
type: string
/microservice_2:
get:
summary: Microservice 2 endpoint
operationId: microservice_2
x-google-backend:
address: https://microservice_2
deadline: 30
responses:
'200':
description: Success
schema:
type: stringBoth `microservice_1` and `microservice_2` are configured with timeout settings of `75s` and `30s` respectively by utilizing the `deadline` parameter of the `x-google-backend` OpenAPI extension.
Azure
Similarly, Microsoft Azure also provides ways to configure the API gateway timeout settings using the `forward-request` option in the XML config when defining inbound and outbound policies. See the below example config:
< !-- api gateway timeout -->
< policies>
< inbound>
< !-- other inbound policies here -->
<base/>
< /inbound>
< backend>
< !-- other backend configs here -->
< !-- set timeout to 180s -->
< forward-request timeout="180"/>
< /backend>
< outbound>
< !-- outbound policies here -->
< base/>
< /outbound>
< /policies>As you can see, using the `forward-request` in the backend, the timeout is set to `180` seconds. You need to make sure to place it within the `<backend>` tags.
On-premise
For on-premise deployments, many options are available. For example, NGINX, HAProxy, Apache servers, etc. can be used for implementing API gateway with timeouts. Let’s take a look at how to customize an NGINX API gateway and set up timeout.
location /api/v1/ {
# Policy configurations here such as authentication, rate limiting, logging, etc.
access_log /var/log/nginx/api/v1/.log main;
location /api/v1/microservice_1 {
proxy_pass http://microservice_1;
proxy_connect_timeout 60s;
proxy_read_timeout 60s;
proxy_send_timeout 60s;
# Other relevant configs here
}
location /api/v1/microservice_2 {
proxy_pass http://microservice_2;
proxy_connect_timeout 30s;
proxy_read_timeout 30s;
proxy_send_timeout 30s;
}
keepalive_timeout 180s;
send_timeout 60s;
client_body_timeout 180s;
client_header_timeout 180s;
# show errors on other
return 404;
}Notice, that you can set up different timeouts for different services. The three key elements for setting timeouts are: `proxy_connect_timeout,` `proxy_read_timeout,` and `proxy_send_timeout.`
Parameters like `keepalive_timeout` and other timeouts are also quite important in this context. These timeouts control different API gateway timeout settings. For more information, check out the documentation.
Conclusion
In this article, we’ve learned what API gateway timeout is, we also dissected timeout types and pinpointed common causes. We also learned the best practices to avoid API gateway timeout with strategies for both the client and server side. Then, we’ve seen implementations and configuration processes of API gateway in various cloud providers and on-premise deployments.
Taking the correct precautions can avoid API gateway timeout errors and ensure that an API gateway is implemented correctly and securely. It is important to make sure, whenever possible, to use industry-standard methods to optimize and monitor the backend services and resources so that the API is resilient and robust enough to handle traffic with ease.

