Blog post
Modern digital services don't fail in isolation. They fail along the seams between you and the vendors you depend on. Yet most vendor decisions are still made on RFP decks, references, and trust, not hard data about how those providers actually perform for your users in each region. That gap is why you keep ending up with "not our fault" incidents, ugly SLA disputes, and vendors you can't defend to finance when budgets tighten. To fix it, engineering, SRE, and procurement need a shared, independent view of internet performance that informs every buy, renew, and exit decision.
This article lays out how to use internet-level performance data to pick the right vendors, by region, at the right cost, and keep your next outage from starting in procurement.
The Real Cost of Vendor Choices Made on Trust
When an outage hits, the incident war room fills with engineers tracing the problem across providers, services, and internal systems. According to the 2024 SRE Report, 66% of SREs say third-party dependencies are the leading cause of unplanned toil. That gap starts in procurement.
Many reliability problems trace back to a vendor decision made months earlier without independent performance data. Someone evaluated a CDN based on the vendor's own benchmarks, signed a multi-year contract, and moved on. When that CDN underperforms in Southeast Asia six months later, the team is stuck troubleshooting a problem that was baked in at the purchasing stage.
A Gatekeeper survey on vendor risk management found that fewer than half of organizations have a structured process for continuously evaluating third-party performance. Most rely on periodic business reviews where the vendor controls the narrative and the data.
The pattern repeats across CDNs, DNS providers, cloud regions, SASE platforms, and ISPs. Teams inherit vendor choices that were made on trust, and they spend their time compensating for the consequences: routing around underperforming providers, manually correlating vendor dashboards, and filing SLA claims after users have already been affected.
Better incident response won't solve this. It starts with how you pick and renew your vendors.
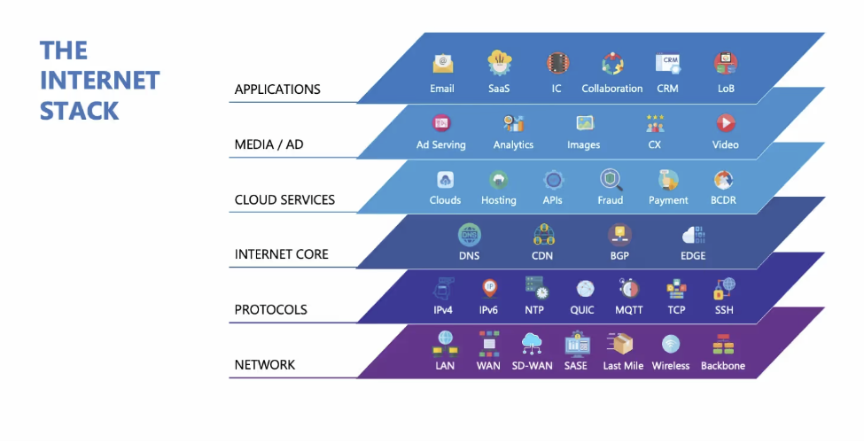
The Internet Stack, mapped by LogicMonitor's Catchpoint IPM. Every layer represents a vendor dependency that affects your users.
What Good Vendor Selection Looks Like When You Have Internet-Level Data
When you choose a CDN, SASE platform, cloud region, or ISP today, you're rarely choosing a single technology. You're choosing how fast, reliable, and costly your user experience will be in specific places around the world. The problem is that most of those choices are made on global benchmarks, vendor dashboards, or proof-of-concept tests that don't reflect day-to-day reality for your users.
Imagine two CDN providers. One delivers median page load times of 520 ms in North America at an annual cost of $1 million. The other delivers 570 ms for $750,000. For many applications, that 50 ms difference is not user-visible, but the quarter-million cost delta absolutely is. With independent, internet-level data, you can see that trade-off clearly and decide whether to standardize, go multi-CDN, or steer only latency-sensitive traffic to the faster provider.
The same logic applies to secure access and network vendors. You may find that your preferred SASE provider performs well in North America but consistently under-delivers in key European markets. Instead of discovering that only after a wave of complaints, you can see it ahead of time and choose either a different primary vendor for that region or a regional partner, with clear expectations baked into the contract.
Good vendor selection is no longer about picking a single global provider. It is about matching the right vendor, or set of vendors, to each critical part of your delivery chain, per region, with measured performance and cost as your guide rails. That requires independent monitoring you control.
How Internet-Aware Observability Changes the Buying Conversation
Most vendor evaluations follow a familiar script: the provider shares its uptime guarantees, hands over a reference customer or two, and presents dashboards filtered to show favorable numbers. The buying team, often working from limited internal data, makes a decision based largely on promises and price.
Internet-aware observability changes that dynamic by giving you your own performance data, collected from outside the vendor's infrastructure, before and after you sign.
Quantify latency against cost, per region. Before you commit to a provider, run independent synthetic tests from the regions where your users are. Measure real latency, availability, and consistency over weeks, not hours. Pair that data with the provider's pricing to build a performance-per-dollar comparison that reflects your traffic patterns, not the vendor's best-case benchmarks.
Compare providers on your terms, not theirs. Vendor dashboards measure what the vendor chooses to measure. Independent Internet Performance Monitoring (IPM) lets you compare CDN response times, DNS resolution, TLS handshake latency, and time-to-first-byte across providers using the same methodology and the same vantage points. That removes the "apples to oranges" problem that makes vendor-supplied data unreliable for side-by-side comparison.
Bake independent SLIs into contracts. Instead of relying solely on the vendor's self-reported SLA metrics, define your own service-level indicators based on independent measurements. Write those into the contract as the agreed source of truth. When there's a dispute, you have data collected by a system neither party controls, which makes resolution faster and fairer.
Shorten proof-of-concept cycles. With continuous internet-level monitoring already in place, you don't need to build a separate test harness for every vendor evaluation. You can compare a new provider's performance against your current stack in real time, using the same infrastructure you use for production monitoring.
The result is a buying conversation grounded in evidence. Procurement gets defensible data. Engineering gets confidence that the vendor can meet real-world requirements. And finance gets a clear picture of what performance costs in each region.
SLA Enforcement as a Feedback Loop Into Vendor Strategy
SLAs are supposed to hold vendors accountable, but in practice they often become shelf documents. The vendor reports its own uptime, the numbers look fine, and the contract renews on autopilot, even when the engineering team's experience tells a different story.
Independent monitoring turns SLA enforcement from a backward-looking exercise into a forward-looking strategy tool. When you measure vendor performance continuously with your own instrumentation, SLA data stops being just a claims mechanism and becomes a signal for vendor strategy decisions: who to keep, who to renegotiate with, and who to replace.
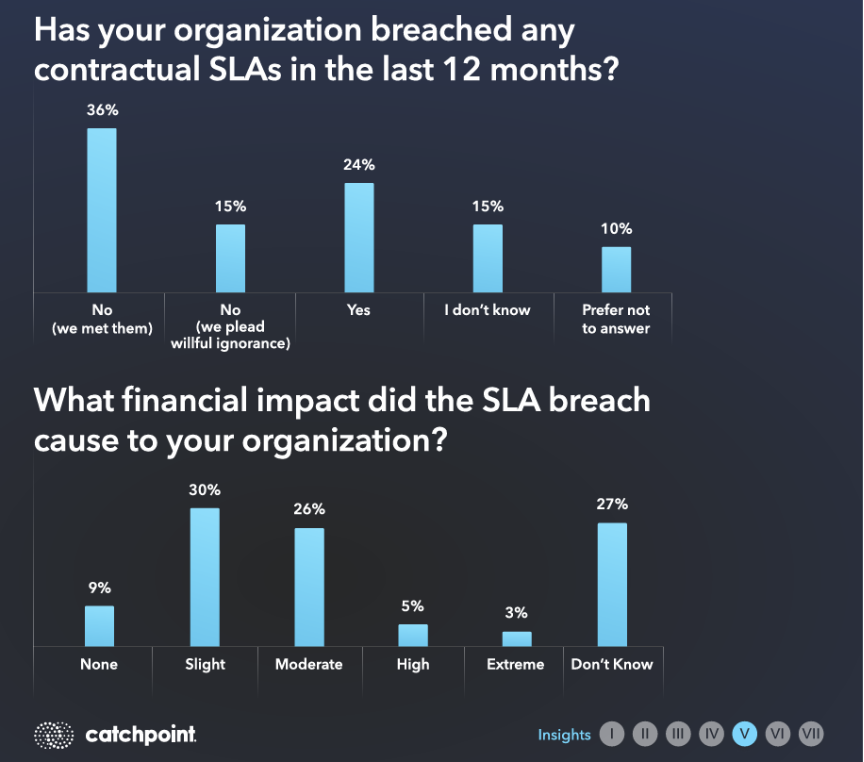
SLA breach data from LM Internet Performance Monitoring, powered by Catchpoint, shows patterns that inform vendor renewal and replacement decisions.
The 2024 SRE Report found that 79% of organizations experienced at least one SLA breach from a third-party provider in the past year, and 44% reported multiple breaches. Those numbers make sense when you consider that most SLA tracking relies on the provider's own telemetry.
With independent data, the SLA conversation changes in three ways.
You catch breaches the vendor doesn't report. Provider dashboards can average away localized outages or define availability windows that exclude planned maintenance. Independent monitoring catches what the vendor's own reporting misses, giving you a complete picture of actual performance.
You build a renewal scorecard. Over a contract cycle, independent SLA data accumulates into a performance record that's useful at renewal time. Instead of relying on the vendor's QBR slides, you can show your procurement team exactly how each provider performed against commitments, broken down by region, time of day, and service type.
You create accountability before problems escalate. When a provider sees that you're tracking performance independently, the dynamic shifts. Issues get addressed earlier. Escalations come with data both sides can reference. And conversations center on shared data instead of competing narratives.
The concept of experience-level objectives (XLOs) takes this further by tying vendor SLAs directly to the end-user experience you're trying to protect. When your SLA framework is connected to user-facing metrics collected independently, enforcement becomes a routine part of vendor management.
Regional Performance Variation and Multi-Vendor Strategy
Global benchmarks hide regional reality. A cloud provider that delivers consistent sub-50 ms latency in US-East might show 120 ms or more in Mumbai or Sao Paulo. A CDN that performs well in Western Europe might struggle in Southeast Asia. If you're making vendor decisions on aggregated global numbers, you're optimizing for an average that doesn't represent any real user.

City-level latency variation for a major cloud provider, visualized using LM Internet Performance Monitoring. The same provider delivers different experiences in different regions.
Independent, city-level monitoring data reveals these disparities before they become user complaints. With that visibility, teams can move beyond single-vendor thinking and adopt a regional, multi-vendor strategy built on measured performance.
Workload placement informed by data. Instead of defaulting to the cloud region closest to your headquarters, place workloads in regions where independent tests show the best performance for your user base. That might mean running primary compute in one provider's Frankfurt region while using another provider's Singapore region for APAC traffic.
Multi-vendor architectures for resilience. When you can see that Provider A outperforms in North America while Provider B is more reliable in Europe, you can design a multi-vendor architecture that uses each where they're strongest. This is about making deliberate, data-informed choices about which provider handles which traffic in which region.
Traffic steering based on live performance. With continuous independent monitoring, you can automate traffic steering decisions based on real-time performance data rather than static DNS policies. If a CDN's latency spikes in a specific region, traffic shifts to the backup provider automatically, and you have the data to explain why.
Regional SLAs that reflect local conditions. A single global SLA doesn't capture the reality of regional performance. With independent monitoring data, you can negotiate region-specific SLA terms that reflect the actual performance characteristics of each market. A vendor that delivers 99.99% availability in North America but only 99.9% in Southeast Asia should have different commitments, and pricing, for each region.
Internet Stack Map is useful here because it shows the full chain of providers and dependencies between your infrastructure and your users in any given region. The internet is a layered, location-dependent set of provider relationships, and your vendor strategy should reflect that.
Vendor-Selection Checklist
Before signing or renewing any contract with a CDN, cloud provider, DNS service, SASE platform, or ISP, your team should be able to answer these questions with independent data, not vendor-supplied reports.
- How does this provider perform for our users in each region we care about? Not global averages or vendor benchmarks. Measured latency, availability, and consistency from the cities and networks where your users connect.
- How does this provider's performance compare to alternatives at the same price point? Can you quantify the performance-per-dollar trade-off for each region, using data collected by the same methodology across all candidates?
- Do we have independent SLIs defined for this provider, and are they written into the contract? If the only SLA metrics come from the vendor's own dashboard, you don't have a meaningful SLA.
- What's this provider's SLA compliance record over the past contract cycle, measured independently? If you can't answer this with your own data, you're relying on the vendor's self-assessment at renewal time.
- Where does this provider underperform relative to its peers, and do we have a plan for those regions? A single-vendor strategy that ignores regional variation is a reliability risk disguised as simplicity.
- Can we detect and respond to performance degradation from this provider in real time, before users report it? If your monitoring depends on the vendor's status page, you'll find out about problems last.
- Is our vendor strategy aligned across engineering, SRE, and procurement? If engineering is troubleshooting vendor problems that procurement locked in without performance data, the process needs to change.
If you can answer all seven with confidence, your vendor management is data-driven. If not, you have gaps that independent IPM can close.
LM Internet Performance Monitoring, powered by Catchpoint, provides teams the independent visibility they need to make these decisions with confidence. It monitors from outside the vendor's infrastructure, across the entire Internet Stack, so you see what your users see rather than what your providers choose to report.
Summary
This is some text inside of a div block.




