Blog post
On July 14, 2025, Cloudflare's 1.1.1.1 public DNS resolver went dark for over an hour, cutting millions of users off from the web. According to Cloudflare's post-mortem, an internal configuration error in a pre-production Data Localization Suite (DLS) service accidentally linked the 1.1.1.1 IP prefixes to a non-production service topology. When an offline test location was added on July 14, it triggered a global configuration refresh that withdrew all 1.1.1.1 prefixes from Cloudflare's data centers worldwide.
Reddit lit up, ISPs got blamed, and users rebooted routers to no avail. But Catchpoint, a LogicMonitor company, had already detected the problem. Internet Sonar flagged the issue at 21:50 UTC, minutes before Cloudflare declared an incident internally at 22:01 UTC. And what Catchpoint's monitoring data revealed during the outage added a surprising layer to the story: a pre-existing BGP hijack by AS4755 (Tata Communications India) that had been invisible under normal conditions was suddenly exposed when Cloudflare pulled its routes.
Outage Overview: What Really Happened to 1.1.1.1?
At 21:50 UTC on July 14, Catchpoint detected a sharp and sudden spike in DNS query failures targeting Cloudflare's public resolver, 1.1.1.1, through Internet Sonar.
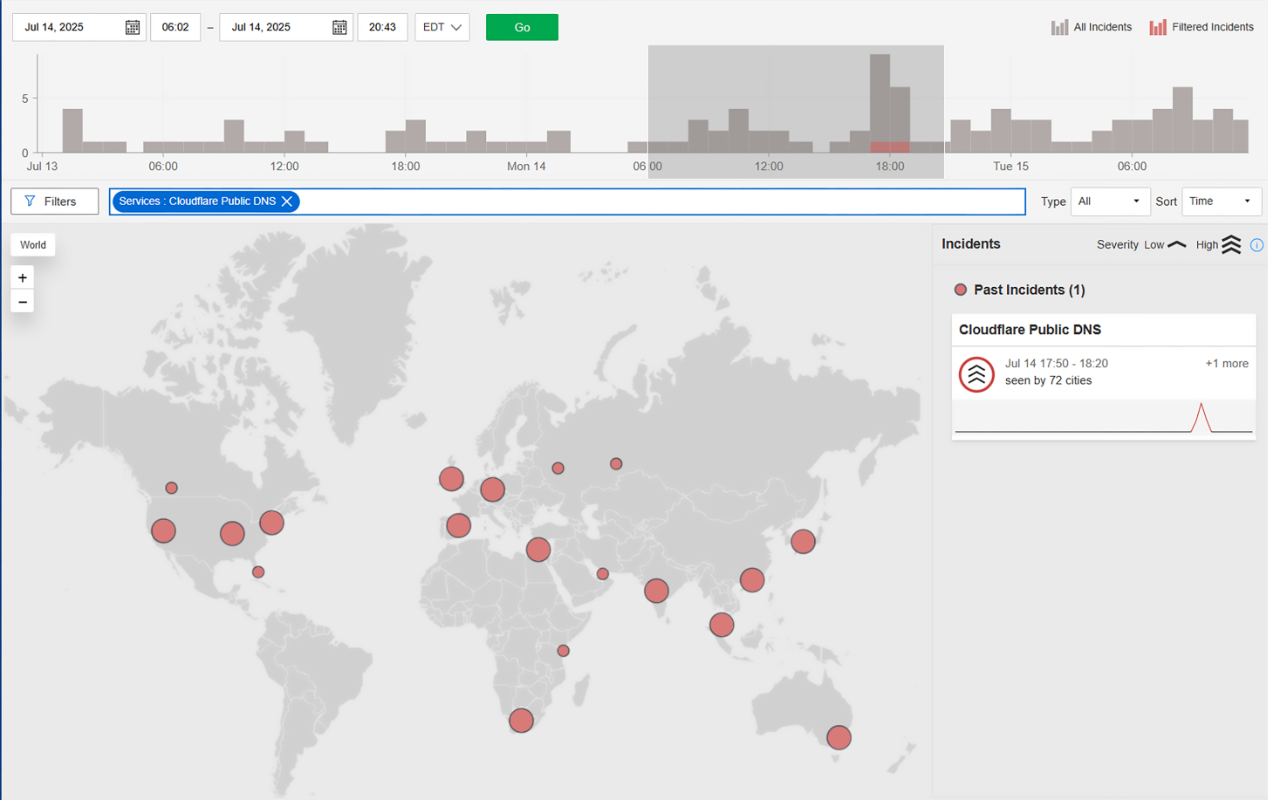
Internet Sonar dashboard visualizing DNS failures in real time
From every angle, it looked like a DNS outage: query timeouts, and toward the end of the incident, ServFail errors.

Scatterplot data indicating failures due to timeouts and server failures
But the DNS servers themselves weren't malfunctioning. The real problem was upstream: Cloudflare's internal misconfiguration had withdrawn the BGP routes that made 1.1.1.1 reachable in the first place. Without valid routes, DNS queries couldn't reach Cloudflare's resolvers, regardless of how healthy those resolvers were.
The Root Cause: A Configuration Error Weeks in the Making
Cloudflare's post-mortem reveals that this outage had a long fuse. On June 6, a configuration change for a pre-production DLS service accidentally included a reference to the 1.1.1.1 Resolver service and its associated IP prefixes. That error sat dormant with no impact for over five weeks.
On July 14, a second change to that same DLS service (adding an offline test location) triggered a global configuration refresh. Because of the June 6 error, the system reduced the 1.1.1.1 prefixes from all locations to a single offline location. The result: a global withdrawal of all 1.1.1.1 prefixes from Cloudflare's data centers. By 21:48 UTC, the impact had started. By 21:52 UTC, DNS traffic to 1.1.1.1 was dropping globally.
As Cloudflare stated: "We're very sorry for this outage. The root cause was an internal configuration error and not the result of an attack or a BGP hijack."
An Unexpected Discovery: The Latent BGP Hijack by AS4755
When Cloudflare withdrew its routes for 1.1.1.0/24, something else became visible. AS4755 (Tata Communications India) started advertising that same prefix. In Catchpoint's BGP monitoring data and RouteViews collectors, the hijacked route appeared and propagated through Tata's global backbone (AS6453) to many networks worldwide.
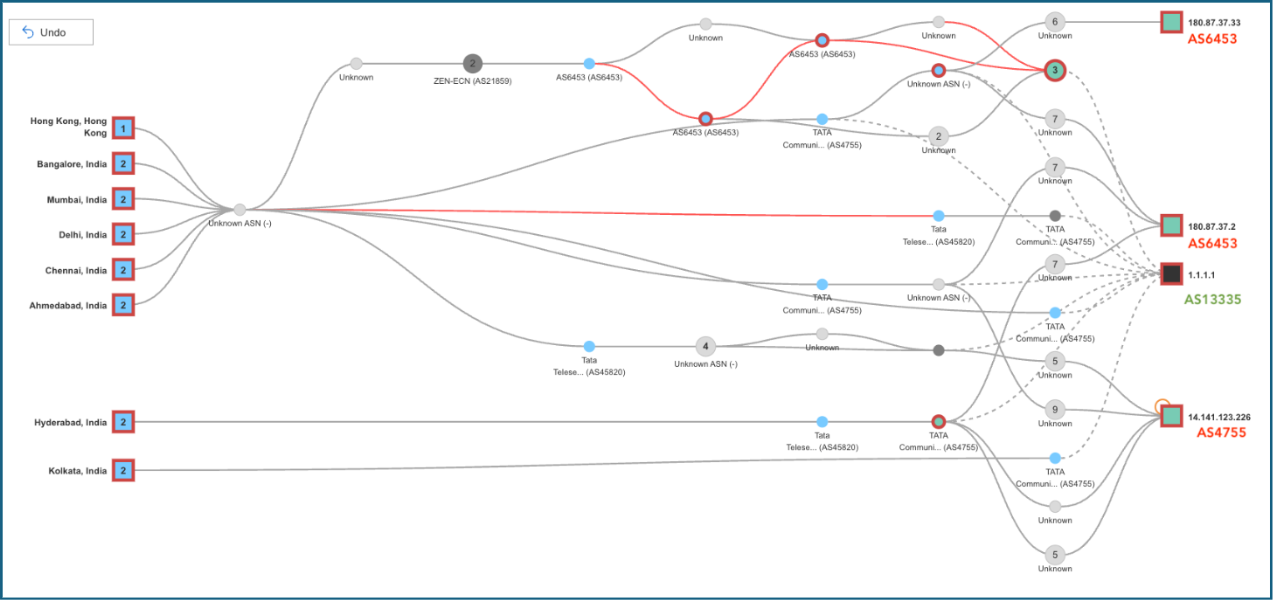
Sankey chart indicating the traffic intended to 1.1.1.1 is routed to other destination IPs
This traceroute visualization tells the story. Each hop is grouped by its Autonomous System Number (ASN) to show how traffic flowed, or failed to. Cloudflare's legitimate origin ASN (AS13335) is visible where valid routes remained, but many traceroutes didn't make it there. A significant number of tests failed with "no route" errors, confirming that the legitimate path had been withdrawn. Others exposed the propagation of the hijacked prefix via unauthorized AS paths.
Cloudflare's post-mortem is explicit on this point: "this BGP hijack was not the cause of the service failure, but an unrelated issue that was suddenly visible as that prefix was withdrawn by Cloudflare." The hijack was pre-existing and latent. It only became visible because Cloudflare's own routes were no longer there to mask it.
This adds a layer to the story that makes it more instructive, not less. It shows how quickly latent routing issues can compound when legitimate routes are withdrawn, even briefly.
RPKI Knew It Was Wrong. Most Networks Didn't Act on It.
While Cloudflare had a valid ROA for 1.1.1.0/24, the hijacked route originated by AS4755 was clearly marked as RPKI Invalid.
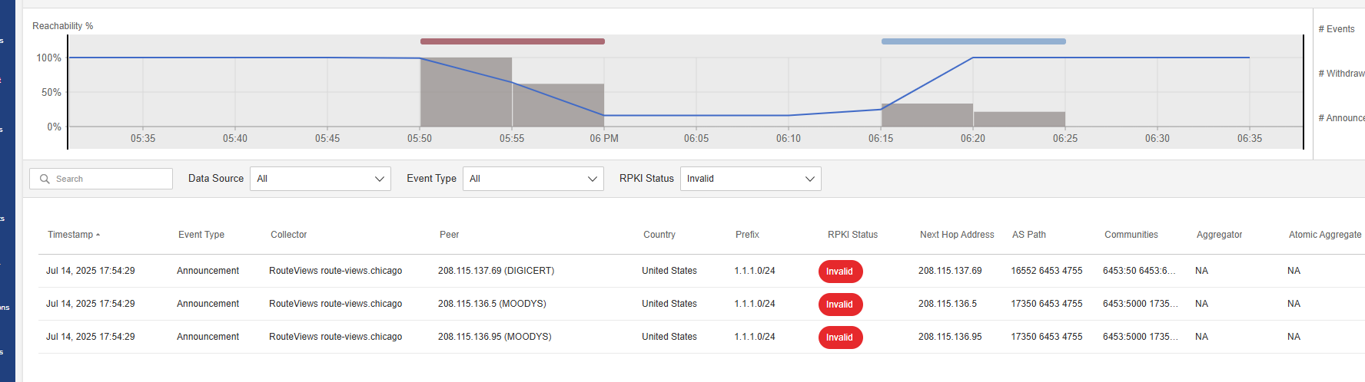
The chart shows a batch of these invalid announcements, captured by Catchpoint's platform (through RouteViews collectors) from peers in the United States. Despite being invalid according to the ROAs, the announcements were accepted and propagated by networks including AS6453.
During this period, many nodes withdrew the valid route via Cloudflare's ASN (AS13335). Some lost reachability entirely, while others adopted the hijacked route pointing toward AS4755. Several ISPs like Lumen and AT&T had no routes at all for 1.1.1.0/24, suggesting they honored RPKI filtering and dropped the invalid announcements from Tata. However, it's unclear why there were no other paths for 1.1.1.0/24 during that window. Under normal circumstances, Cloudflare's own announcements would reach these networks.
Cloudflare was careful enough to create a proper ROA stating that the prefix hosting their DNS service can be originated only by Cloudflare's AS number (AS13335), as can be seen here. Tata itself is known to apply filtering based on RPKI, as Cloudflare states on the Is BGP safe yet? website. An open question remains: why did Tata's RPKI filtering not catch this announcement? One possibility is that filtering was not applied to routes originated by AS numbers within their own group, but Cloudflare's post-mortem notes only that they are "following up with Tata Communications."
Real-World Impact: What It Meant for End Users
The effect for end users was immediate and confusing:
- Websites didn't load. Most websites and services were fully operational, but users couldn't reach them. Without DNS resolution, domain names couldn't be translated into IP addresses, so browsers returned errors or spun endlessly.
- Apps appeared broken. Streaming platforms, messaging apps, payment gateways, and enterprise tools all rely on domain name resolution to function. When DNS failed, these services appeared to be "down" or disconnected, prompting support tickets, user complaints, and internal confusion.
- Local troubleshooting led nowhere. Many users assumed the problem was on their end. They rebooted routers, toggled Wi-Fi, or contacted their ISP, wasting time while the root cause remained external and invisible to them.
- Social platforms reacted, but couldn't diagnose. With no immediate explanation from Cloudflare, users turned to Reddit and DownDetector for confirmation. These platforms reflected what people reported, but provided no diagnostics, timelines, or guidance.
The outage lasted 62 minutes. Cloudflare deployed a revert at 22:20 UTC, and traffic returned to normal by 22:54 UTC.
Lessons from the 1.1.1.1 Outage
Internal Misconfigurations Are a Top Outage Risk
This outage didn't come from an external attack or a rogue network. It came from a configuration change in a pre-production service that accidentally referenced production infrastructure. The error sat dormant for over five weeks before a routine change activated it. For organizations depending on third-party services, the takeaway is clear: you can't assume that a provider's internal processes will catch every error before it reaches production.
Monitor the Full Internet Stack, Not Just Your Own Systems
Mission-critical services depend on external systems like DNS, BGP, and transit networks. DNS is a single point of failure: if it breaks, nothing works, regardless of how healthy your backend is. Public resolvers like 1.1.1.1 are foundational to connectivity, and when they become unreachable, even healthy services appear broken. A thorough monitoring strategy covers the entire Internet Stack, including protocols like BGP and DNS. This is where LM Internet Performance Monitoring becomes essential, giving teams visibility into the layers of the Internet that sit outside their direct control but directly affect end-user experience.
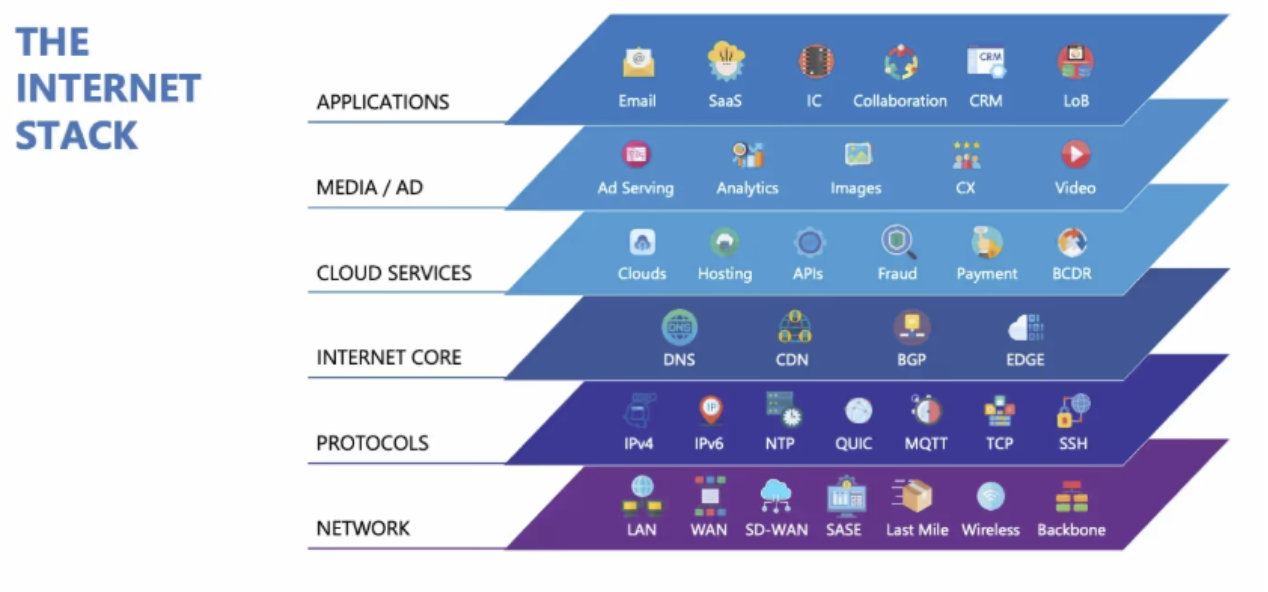
A visual representation of the Internet Stack
Your customers won't know it's Tata or Cloudflare's fault. They'll blame you.
Latent Routing Issues Compound Fast
The BGP hijack by AS4755 was pre-existing and invisible under normal conditions. It only became a visible problem when Cloudflare's routes were withdrawn. This demonstrates how fragile routing can be: latent issues that sit quietly for months (or longer) can surface the moment a legitimate route disappears, compounding an already serious outage.
ISPs Must Enforce RPKI Filtering
The hijacked route for 1.1.1.0/24 was marked RPKI Invalid. It should have been rejected. Networks that properly implemented RPKI-based origin validation did reject it, and their users remained unaffected. Filtering invalid routes is no longer optional for a resilient Internet.
Early Detection Matters
Outages unfold fast. To get ahead of them, organizations need proactive Internet Performance Monitoring, with tools like Internet Sonar and Internet Stack Map. Together, they help teams quickly answer: "Is this our problem, or something else?"
In the case of this outage, Internet Sonar flagged the issue minutes before Cloudflare declared an incident internally at 22:01 UTC, a window that's invaluable when service continuity and SLAs are on the line. Combined with LM Envision for infrastructure and cloud telemetry, and Edwin AI for intelligent prioritization and guided action, teams get a unified view from user to code, so they can move from detection to resolution faster.
Don't Rely on Social Signals for Outage Detection
By the time Reddit and DownDetector light up, the damage is done. Social chatter is reactive, fragmented, and often misleading. Data-driven monitoring tools help you spot outages before your users do, not after they've started complaining.
Specify a Backup DNS Resolver
If you're an end user, specify a backup DNS resolver from a different provider. For example, if your primary is Cloudflare (1.1.1.1), set Google (8.8.8.8) as your secondary. It's a simple step that can keep you online when one DNS service hits trouble.
Conclusion
The Cloudflare 1.1.1.1 outage was caused by an internal configuration error. A pre-production service change accidentally pulled production DNS routes offline, and a latent BGP hijack that had been invisible for an unknown period suddenly surfaced to make things worse. The incident lasted 62 minutes and affected millions of users who rely on 1.1.1.1 for DNS resolution.
This incident reinforces that resilience requires more than uptime. It demands visibility, validation, and vigilance across the full Internet Stack. Whether you operate a global network or rely on one, protecting users from outages like this means monitoring beyond your perimeter, enforcing RPKI, and responding to failures with precision instead of guesswork.
Cloudflare deserves credit for publishing a detailed and transparent post-mortem. Sharing this level of detail reinforces trust and helps the broader Internet community learn and improve.
Summary
This is some text inside of a div block.




