Webinar
Catch BGP Issues Before They Impact Your Business
Catch
BGP issues
network issues
CDN issues
application issues
DNS issues
cloud issues
ISP issues
before they impact your business
From the user to the application, Catchpoint gives you insights across the Internet Stack to anticipate, detect and fix problems fast.
Trusted by
9
of the top 10 Forbes Digital Companies
6
of the top 6 Cloud Providers
9
of the top 10 CDN Providers
7
of the top 10 Publicly-traded Software Companies by Revenue

Gain full visibility into your Internet Stack
Today, the Internet is your network.
With Catchpoint Internet Performance Monitoring (IPM), you get clear, actionable insights into your Internet Stack performance (CDN, DNS, VPN/SASE, ROBO, and BGP) to fix issues quickly and ensure a smooth user experience.

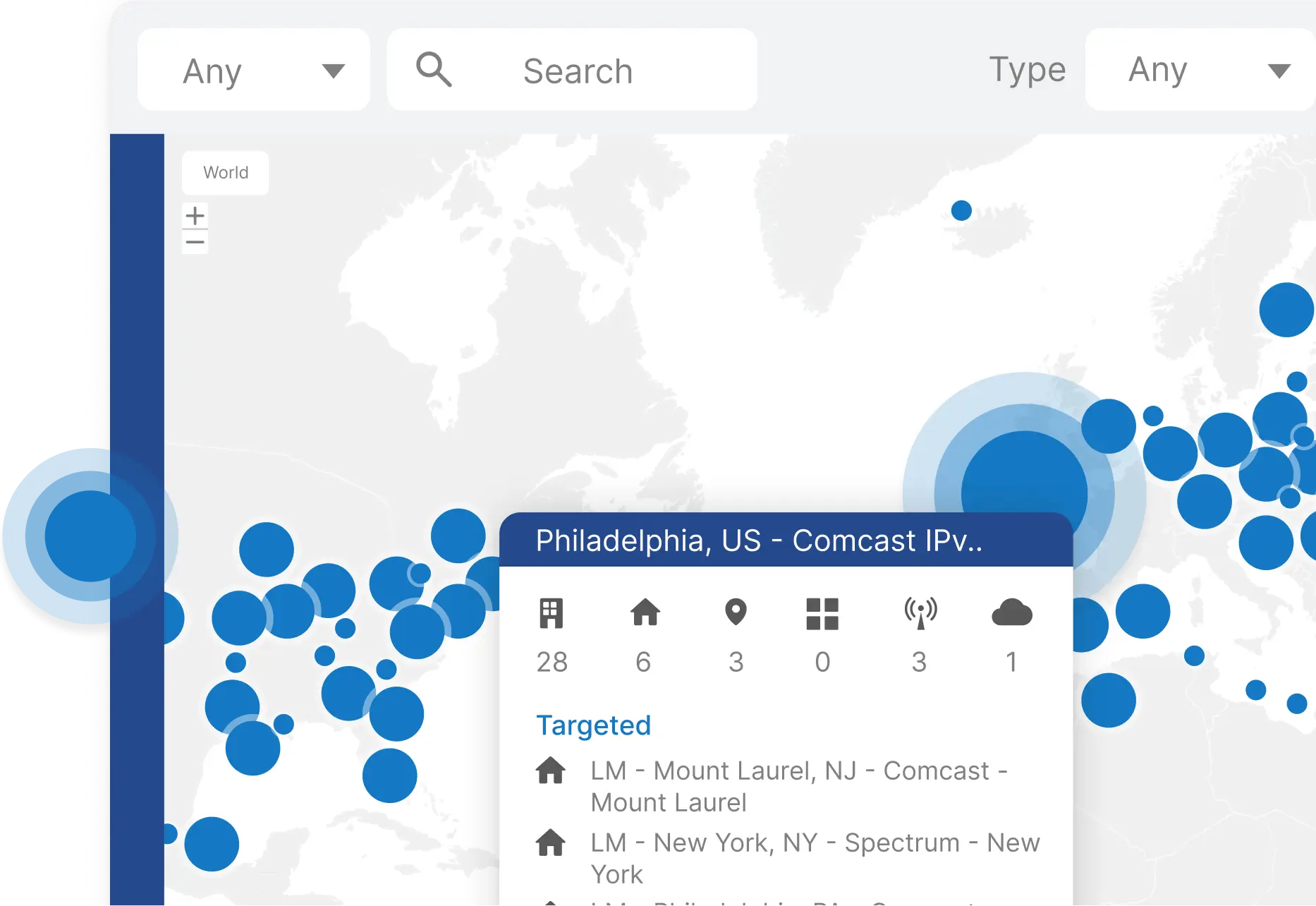
Observe performance from where your users are
Optimize performance, availability, reliability, and reachability from where it matters most: where your users are.
Our global observability network has over 2,600 vantage points inside your network, inside wireless carriers, at routing points, and on core Internet infrastructure across the world.
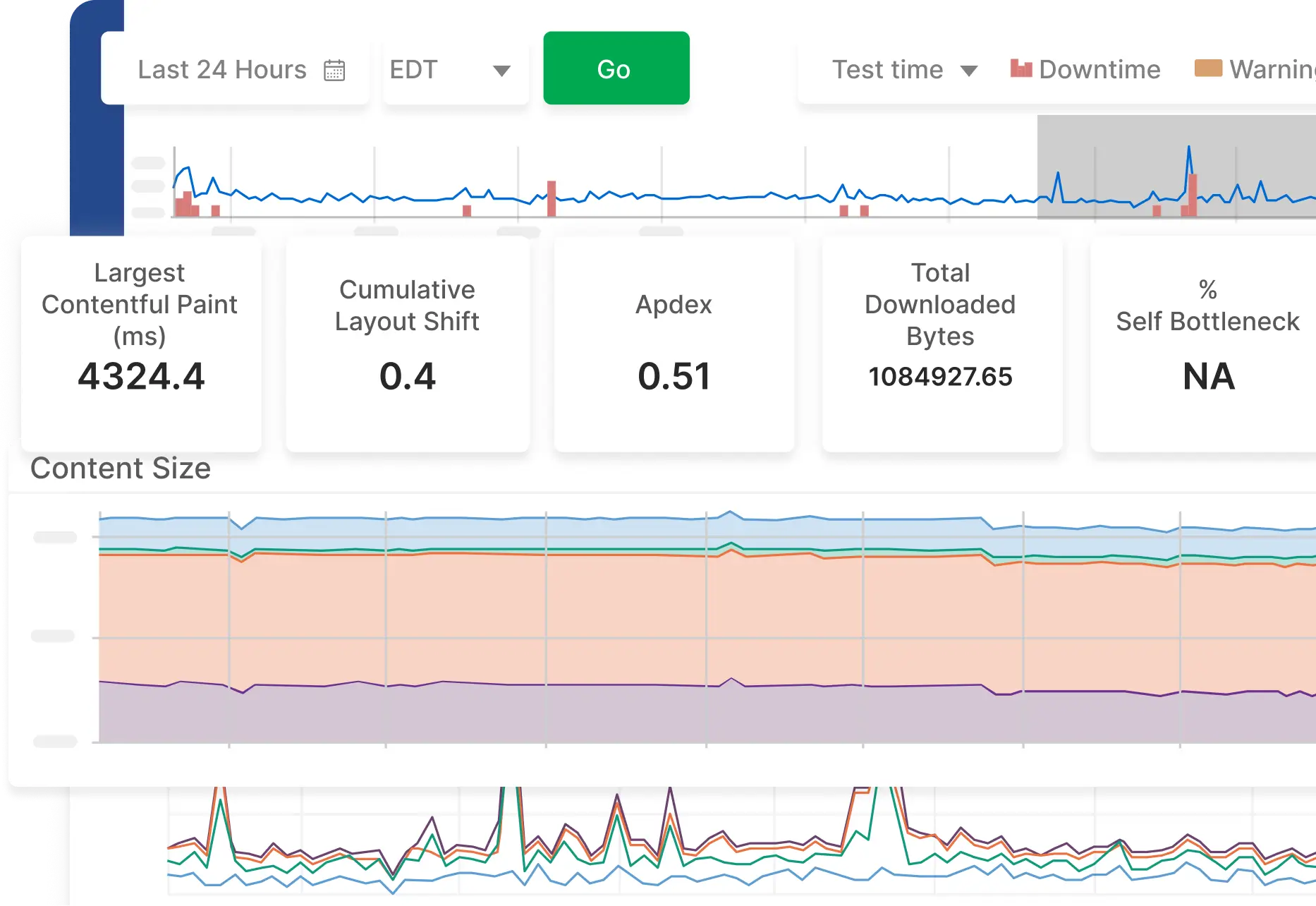
Fix issues faster with actionable, intelligent analytics
Catchpoint's intelligent analytics allow you to distill mountains of data into meaningful insights quickly, enabling you to focus your troubleshooting and optimization efforts on elements such as a particular region, stack component, or SEO rankings.
Your Internet Resilience ally
Catchpoint’s award-winning Managed Services team is available to augment your team and provide best practices, hand-on guidance, or a complete monitoring-as-a-service solution for your organization.
Catchpoint is an ally you can always rely on.

Stop Internet outages in their tracks. We can help.
Hear from our customers

Martin Norato Auer
VP, CX Observability Services
SAP
We get Catchpoint alerts within seconds when a site is down and within three minutes, identify exactly where the issue is coming from and inform our customers and work with them.”
Read story

Charles Conley
Manager, IT OPS
Their support has been fantastic - really taking the time to show us new features as they come out - and they are coming out with new features very frequently."
Read story

Gary Ballabio
VP Technology Partnerships
It really came down to the service itself and what it was providing us. We can run simultaneous tests with Catchpoint from different agents all over the world, which gives us a real comparison of what website performance looks like."
Read story
What’s new at Catchpoint
The SRE Report 2024 is now available!
Discover the insights of over 400 global reliability practitioners.
Featuring esteemed contributions from across the field, including Steve McGhee, Kurt Andersen, and Niall Murphy.

Popular resources
Webinar
Avoid Observability Failure: Hybrid Enterprises Must Complement APM with Internet Performance Monitoring
Webinar