

Blog post
When AWS's massive outage struck, it didn't just take down cloud services, apps, and enterprise platforms. It also knocked out many of the monitoring systems organizations depend on for real-time answers. Observability companies, including Datadog, New Relic, Checkly, Dynatrace, SpeedCurve, and Splunk Observability, lost visibility or functionality precisely when organizations needed them most.
In those first, chaotic 15 to 20 minutes, before teams knew the problem was AWS East, most organizations were flying blind. Their monitoring tools live in the very cloud that just failed, so there was no way to see what was really happening.
Ensuring ongoing visibility during events like these requires a fundamentally different approach to monitoring architecture. Here's what organizations can do today to protect themselves before the next major outage hits.
What happens when your monitoring fails?
As Adrian Cockcroft writes, monitoring systems themselves can fail, and when they do, organizations lose the visibility they need to respond effectively. You need monitoring that's independent of the systems being monitored.
The AWS outage demonstrated this principle. Organizations that relied solely on cloud-hosted monitoring tools found themselves blind to the very outage impacting their operations. Your monitoring strategy must account for the possibility that your monitoring tools themselves can fail.
Organizations that haven't audited their monitoring architecture should do so now. These five steps are a practical starting point.
#1. Your monitoring can't live in the same cloud you're trying to monitor
Relying on monitoring tools hosted exclusively in the same cloud environment as your critical systems creates a significant risk. If that cloud experiences an outage, both your production systems and your monitoring go down together, leaving you without visibility at the most critical moment.
Even as we wrapped up this post at 4pm ET, many of the leading monitoring platforms still reported incidents on their status pages.
#2. Map your critical third-party dependencies
Most organizations aren't fully aware of all the dependencies their digital systems rely on. If you're a retailer, for example, even if your website is architected to survive a cloud provider outage, it still depends on DNS, BGP routing, SSL certificates, CDN services, payment processing systems, third-party APIs, cloud services, and dozens of smaller components. Any of these can fail and impact your operations.
Action: Conduct a thorough audit of your critical systems. Internet dependency mapping tools like Internet Stack Map can help you visualize and document every protocol, service, and third-party vendor your operations rely on, making it easier to pinpoint single points of failure and strengthen your resilience.
#3. Develop a resilience plan
For each critical system, develop a resilience plan that includes multi-cloud or multi-region architectures, redundant systems, and documented fallback procedures. Cloud engineering teams have embraced Chaos Engineering, a philosophy of deliberately testing failure scenarios to understand how systems break and how to respond. Things will break, and the only variable is whether you're prepared when they do.
Action: Implement chaos testing, tabletop exercises, and regular drills. Build redundancy where it matters most. Document and practice your incident response playbook.
#4. Invest in Internet Performance Monitoring
Many organizations haven't invested enough in Internet Performance Monitoring (IPM), a solution that provides visibility into the performance and availability of every aspect of the internet stack, internal and external. As part of the LogicMonitor platform, Catchpoint IPM gives you external, cloud-independent awareness to detect, diagnose, and respond to outages across the entire stack. Many cloud-hosted monitoring tools lack visibility into the Internet path itself. IPM closes that gap.
Action: Deploy IPM to ensure you have external visibility into cloud providers, DNS, CDN, and other critical services.
#5. Make resilience a priority
Resilience shouldn't be an afterthought. Internet systems are interdependent and fragile. Invest in the planning, redundancy, runbooks, and processes needed to make resilience a reality.
Investing in resilience can feel difficult amidst the push for consolidation and rising observability costs. But prioritizing high-quality, actionable signal reduces costs while improving visibility. LogicMonitor's unified platform, combining LM Envision, Catchpoint IPM, and Edwin AI in a single telemetry pipeline, is built around signal quality and purposeful AI.
Some organizations are creating dedicated Chief Resilience Officer roles, a signal of how seriously the industry is taking Internet dependency risk.
How Catchpoint Internet Sonar caught the incident 16 minutes ahead of AWS reporting it
Catchpoint Internet Sonar detected the AWS outage at 06:55 AM UTC, a full 16 minutes before AWS updated its status page at 07:11 AM UTC.
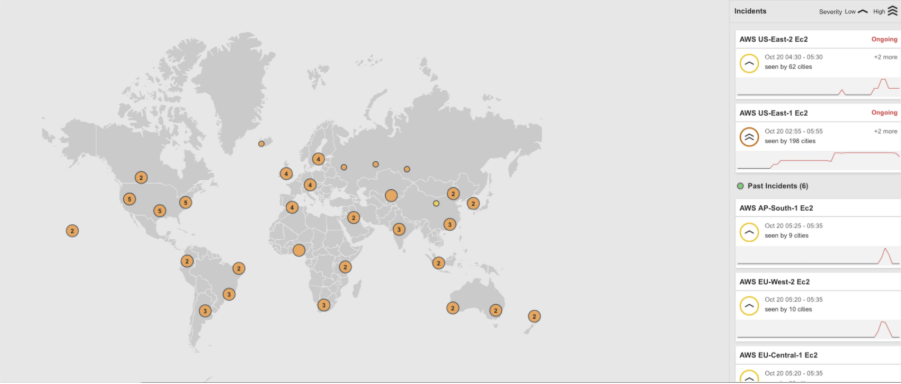
Catchpoint Internet Sonar dashboard showing global impact of the AWS outage, with Asia Pacific, Europe, Middle East and Africa, Latin America and North America affected
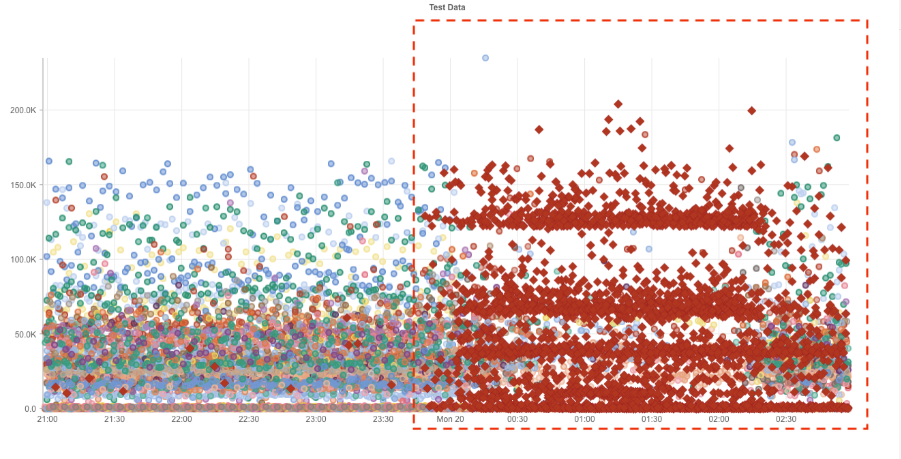
Scatterplot visualization of test performance and failures from dozens of monitoring locations and services during the AWS outage. Across the timeline, there's a sharp spike in failed tests and dramatically increased response times.
Those 16 minutes have a real cost. Without visibility, teams can't triage, escalate, or communicate status to the business. Every minute without visibility extends the incident's impact on customers, revenue, and internal confidence.
How early detection was possible
Catchpoint Internet Sonar continuously monitors billions of signals in real time, providing alerts and updates on key services worldwide. Take a look at the Live Internet Outages Map powered by Catchpoint Internet Sonar.
Organizations whose monitoring platforms relied on AWS likely had limited visibility into this incident. In many cases, teams learned about the outage from customer complaints, flooded support lines, or social media chatter before their tools reported anything. Some were in the dark for 16 minutes or longer about what was actually wrong.
Conclusion
The AWS outage showed that even well-resourced organizations can lose monitoring visibility within minutes when their tools depend on the infrastructure that just failed. Every layer of the Internet Stack, from cloud providers and DNS to CDN, SSL certificates, APIs, and payment processors, introduces risk. The next failure could come from any of them. Outages will happen. What matters is how prepared your organization is to respond.
Organizations that rely solely on cloud-hosted monitoring tools risk losing visibility to the very incidents that threaten their operations. Organizations that want to avoid the same outcome should adopt independent external monitoring, map their dependencies, invest in resilience planning, and practice their incident response before the next outage.
Summary
This is some text inside of a div block.




